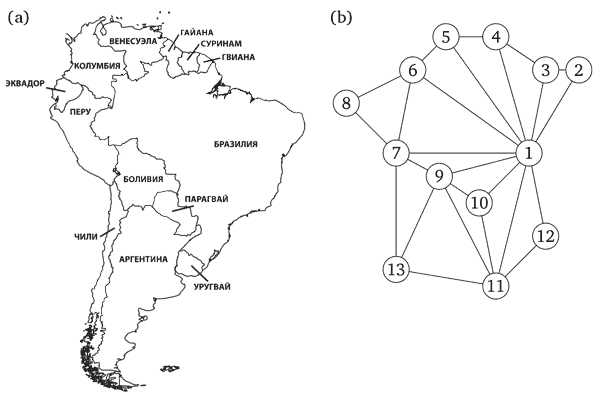
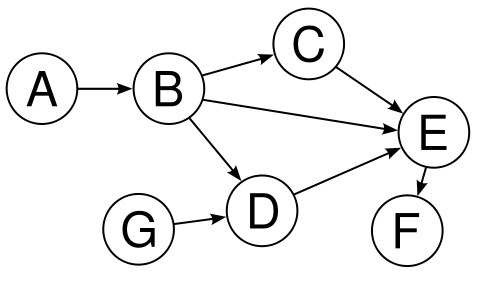
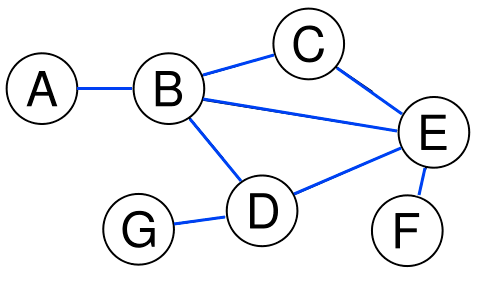
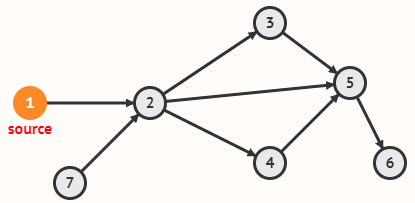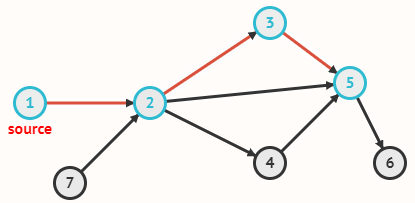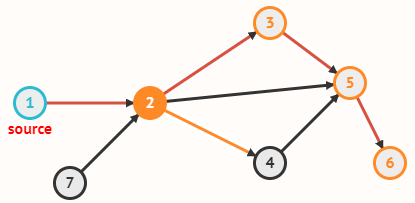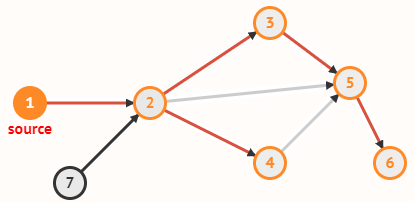
Граф задаётся множеством вершин V и множеством рёбер E, соединяющих пары вершин.
(Английская терминология: вершина называется vertex или node, а ребро — edge.)
В примере с картой V = {1, 2, 3, ..., 13}, а рёбра из E соединяют страны,
граничащие друг с другом (в частности, E содержит рёбра {1, 2}, {9, 11} и
{7, 13}). Отношение «быть соседом» симметрично, так что ребро из x в y возникает одновременно с ребром из y в x.
Такие рёбра называются неориентированными (undirected),
а соответствующий граф — неориентированным графом (undirected graph).
Бывают и несимметричные отношения, и их изображают ориентированными рёбрами (directed edges).
В ориентированном графе наличие ребра из x в y не гарантирует наличие ребра из y в x.
Если явно не указано обратное, то рассматривают только графы без петель (loop) и без кратных рёбер (multiple edge).
Такие графы называются простыми (simple).
Самые простые графы — это деревья.
Во многих задачах, связанных с графами, используется обходы графа,
в результате которых в графе выделяются деревья, состоящие из некоторых вершин графа и некоторых его рёбер.
У этих деревьев отмечена вершина, которая называется его корнем (root).
Дерево с отмеченной вершиной — корнем — называется корневым деревом (rooted tree).
В корневых деревьях чётко различаются путь к корню и путь от корня.
Сосед вершины на пути к корню называется её родителем (parent).
Соседи вершины на пути от корня называются её детьми или сыновьими вершинами (child, children).
Все вершины на пути из вершины к корню, кроме исходной, называются её предками (ancestor).
Все вершины на пути из корня называются потомками (descendant).
Вершины, у которых общий родитель, называются братьями (sibling).
И наконец вершины, у которых нет потомков, называются листьями (leaf, leaves, terminal vertex).
Рассмотрим граф c n=∣V∣ вершинами v1,…,vn.
Его матрицей смежности (adjacency matrix) называется (n×n)-матрица a,
в которой
aij={1,0еслиестьреброизviвvjиначе
Матрица смежности неориентированного графа, таким образом, симметрична (aij=aji).
В таком представлении мы можем за время O(1) проверить, соединены ли
данные вершины ребром (посмотрев на один элемент массива).
В то же время хранение матрицы требует памяти O(n2),
что во многих случаях неэкономно.
Альтернативное представление — список смежности (adjacency list).
Требуемая при этом память пропорциональна размеру графа (сумме числа вершин и числа рёбер).
Элементами списка смежности являются списки, по одному для каждой вершины графа.
Для вершины u в таком списке хранятся вершины, в которые ведут рёбра из u,
то есть вершины v, для которых (u,v)∈E.
Для ориентированного графа каждое ребро входит только в один из этих списков (для начальной вершины),
а для неориентированного в два (для двух концов ребра).
Список смежности, таким образом, требует памяти O(∣V∣+∣E∣).
Проверка наличия ребра (u,v) теперь требует просмотра списка вершины u
(что может быть больше O(1) шагов, если вершины хранятся именно в списке, а не в множестве или словаре).
Зато в этом представлении легко просмотреть всех соседей заданной вершины (что часто бывает необходимо).
Список смежности для неориентированного графа симметричен (если u содержится в списке для v, то и v содержится в списке
для u).
Что лучше? Ответ зависит от отношения между числом вершин ∣V∣ и числом рёбер ∣E∣.
Заметим, что ∣E∣ может быть довольно малым — порядка ∣V∣
(если ∣E∣ сильно меньше ∣V∣, то граф уже вырожденный — в частности, содержит изолированные вершины).
Или же довольно большим — порядка ∣V∣2 (если граф содержит все возможные рёбра).
Графы с большим числом рёбер называют плотными (dense), с малым — разреженными (sparse).
Выбирая алгоритм, полезно понимать, с какими графами ему в основном
придётся иметь дело. Важно это и при хранении: если хранить веб-граф, в
котором больше восьми миллиардов вершин, в виде матрицы смежности,
то занимать она будет миллионы терабайтов, что сравнимо с общей ёмкостью всех жёстких дисков в мире.
И дальше, скорее всего, будет только хуже (матрица может расти быстрее, чем производство дисков).
А вот хранить граф Интернета в виде списка смежности вполне разумно, поскольку хранить нужно несколько десятков миллиардов гиперссылок, каждая из которых будет занимать в списке всего несколько байтов, и такого размера диск поместится в карман.
Такая разница происходит из-за того, что граф Интернета очень разрежен: страница содержит в среднем
пару десятков ссылок на другие страницы — из нескольких миллиардов возможных.
A = set() # Пустое множество
A = {1, 2, 'hello'} # Явное перечисление элементов
A = set('hello') # Множество букв в строке
B = [1, 2, 1, 2]; A = set(B) # Множество из списка или любого итерируемого объекта
A = {i**2for i in range(10)} # Генератор множеств
Работа с элементами множеств
C = {1, 2, 'hello'}
for elem in C: # Перебираем все элементы множества
print(elem)
sorted(C) # Список из отсортированных элементов множества1in C # Проверка принадлежности
A.add(3) # Добавление элемента
A.remove(3) # Удаление элемента, который есть в множестве
A.discard(4) # Удаление элемента, которого может не быть в множестве
A.pop() # Извлечение случайного элемента из множества с удалением его
Операции с множествами
len(A) # Количество элементов в множестве
A | B # Возвращает множество, являющееся объединением множеств A и B.
A |= B # Добавляет в множество A все элементы из множества B.
A & B # Возвращает множество, являющееся пересечением множеств A и B.
A &= B # Оставляет в множестве A только те элементы, которые есть в множестве B.
A - B # Возвращает разность множеств A и B (A, но не B).
A -= B # Удаляет из множества A все элементы, входящие в B.
A ^ B # Возвращает симметрическую разность множеств A и B.
A ^= B # Записывает в A симметрическую разность множеств A и B.
A <= B # Возвращает true, если A является подмножеством B.
A >= B # Возвращает true, если B является подмножеством A.
A < B # Эквивалентно A <= B and A != B
A > B # Эквивалентно A >= B and A != B
Про словари
Задание словарей
D = {} # Пустой словарь
D = {1: 'a', 2: 'b'} # Явное перечисление
D = dict([(1, 'a'), (2, 'b')]) # Словарь из списка пар элементов
D = dict(zip([1, 2], ['a', 'b'])) # Словарь из итерируемого объекта, возвращающего пары элементов (ключ-значение)
D = {i: chr(i + ord('a')) for i in range(1, 3)} # Генератор словарей
Работа с элементами словаря
len(D) # Количество элементов в словаре
D[key] # Поиск по ключу, который есть в словаре
key in D # Проверка принадлежности словарю
D[key] = value # Установка или изменение значенияdel D[key] # Удаление ключа, который есть в словаре
value = D.pop(key) # Удаления ключа вместе с возвращением значения
value = D.pop(key, no_key_value) # Удаления ключа вместе с возвращением значения. Если ключа нет, то no_key_value
key, value = D.popitem() # Извлечение из словаря пары (ключ, значение) с удалением ключа
D.get(key, no_key_value) # Значение по ключу, no_key_value, если ключа нет
D[key] = D.get(key, 0) + 1# Самая простая реализация счётчикаfor key in D: # Перебираем все ключи
print(key, D[key])
for key, value in D.items(): # Перебираем все пары (ключ, значение)
print(key, value)
for value in D.values(): # Перебор всех значений
print(value)
sorted(D) # Отсортированный список ключей
sorted(D.values()) # Отсортированный список значений
sorted(D.items()) # Отсортированный по ключу список пар (ключ, значение)
sorted(D.items(), key=lambda x: x[1]) # Отсортированный по значению список пар (ключ, значение)
# Список смежности и матрица смежности: туда и обратно
A: От матрицы смежности к списку ребер, неориентированный вариант
Простой неориентированный граф задан матрицей смежности, выведите его представление в виде списка ребер.
Входные данные включают число n — количество вершин в графе,
а затем n строк по n чисел, каждое из которых равно 0 или 1, — его матрицу смежности.
Выведите список ребер заданного графа (в любом порядке).
B: От списка ребер к матрице смежности, неориентированный вариант
Простой неориентированный граф задан списком ребер, выведите его представление в виде матрицы смежности.
Входные данные включают число n — количество вершин в графе, и число m — количество рёбер.
Затем следует m пар чисел — ребра графа. Выведите матрицу смежности заданного графа.
5 3
1 3
2 3
2 5
0 0 1 0 0
0 0 1 0 1
1 1 0 0 0
0 0 0 0 0
0 1 0 0 0
IDE
C: От матрицы смежности к списку ребер, ориентированный вариант
Ориентированный граф задан матрицей смежности, выведите его представление в виде списка ребер.
Входные данные включают число n — количество вершин в графе,
а затем n строк по n чисел, каждое из которых равно 0 или 1, — его матрицу смежности.
Выведите список ребер заданного графа (в любом порядке).
D: От списка ребер к матрице смежности, ориентированный вариант
Простой ориентированный граф задан списком ребер, выведите его представление в виде матрицы смежности.
Входные данные включают число n — количество вершин в графе, и число m — количество рёбер.
Затем следует m пар чисел — ребра графа. Выведите матрицу смежности заданного графа.
В графе в отличие от корневого дерева нет корня и нет разницы между предками и потомками.
Все рёбра равнозначны.
Поэтому удобно хранить граф в виде словаря, ключами которого являются все вершины,
а значениями — множество вершин, соединённых с данной.
Если граф неориентированный, то каждое ребро (v, w) "хранится" сразу в двух множествах.
Пока мы будем иметь дело только с простыми графами без изолированных вершин,
поэтому каждая вершина участвует в каком-то ребре.
Следовательно, множество всех вершин графа будет определяться как множество вершин всех рёбер.
В спортивном программировании вершины графа — обычно последовательные числа от 1 до n.
В этом случае граф лучше хранить как список списков или вектор векторов (в C++).
Однако в этом разминочном листке предполагается использование питона и словаря множеств.
Это удобно и быстро.
Спортивные модификации алгоритмов будут в отдельном листке.
Программа получает на вход число рёбер в ориентированном графе N.
Далее следует N строк, задающие рёбра графа.
Каждая строка имеет вид откуда_ребро куда_ребро.
Программа должна сформировать словарь digraph смежности ориентированного графа
и вывести его при помощи функции pprint из модуля pprint.
Реализуйте функцию digraph_from_input(), которая считывает граф в таком формате из стандартного ввода
и возвращает словарь digraph.
Программа получает на вход число рёбер в неориентированном графе N.
Далее следует N строк, задающие рёбра графа.
Каждая строка имеет вид откуда_ребро куда_ребро.
Программа должна сформировать словарь graph смежности неориентированного графа
и вывести его при помощи функции pprint из модуля pprint.
Реализуйте функцию graph_from_input(), которая считывает граф в таком формате из стандартного ввода
и возвращает словарь graph.
Ориентированный граф кратко называется орграфом.
Для краткости далее под графом всегда будет пониматься только неориентированный граф.
Из орграфа всегда можно сделать граф, убрав стрелочки с вершин.
На вход подаётся строка, в которой записан словарь digraph.
Его можно записать в переменную при помощи кода
digraph = eval(input())
Сделайте из этого орграфа неориентированный граф и выведите его при помощи pprint.
Выведите входящую (количество входящих рёбер, indegree) и исходящую (количество исходящих рёбер, outdegree) степень каждой вершины.
Вершины должны выводиться в лексикографическом порядке.
Квадратом графа называется граф с тем же множеством вершин, что и исходный,
но в котором из вершины v проведено ребро в w,
если в исходном графе из вершины v можно попасть в w не более, чем за 2 шага.
Выведите квадрат орграфа.
Транспонированным графом называется граф с тем же множеством вершин, что и исходный,
но в котором из вершины v проведено ребро в w тогда и только тогда,
когда в исходном графе есть ребро из w в v.
На вход подаётся строка, в которой записан словарь digraph.
Транспонируйте этот орграф и выведите его при помощи pprint.
Дополнением или обратным графом называется граф с тем же множеством вершин, что и исходный,
но в котором из вершины v проведено ребро в w тогда и только тогда,
когда в исходном графе нет ребра из v в w.
На вход подаётся граф в формате из задачи F.
Создайте обратный граф и выведите его при помощи pprint.
Выполните обход графа в ширину начиная с этой вершины.
Сложность получившегося алгоритма должна быть O(∣V∣+∣E∣).
8
A B
B C
B D
B E
C E
D E
E F
G D
A
A
B
C
E
D
F
Подсказка (а также прочитать после решения)
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Здесь нужно делать всё также, как и для деревьев, только дополнительно нужно хранить множество посещённых вершин и не ходить в них повторно.
Есть два самых простых способа делать такой обход: при помощи слоёв или при помощи очереди.
В разных случаях конкретный способ может быть удобнее благодаря некоторым бонусам.
Решение при помощи слоёв:
Будем хранить два множества: множество элементов, которые необходимо обойти на текущем уровне дерева, а также множество встреченных элементов следующего уровня.
Сначала добавляем в первое множество начальную вершину, а второе оставляем пустым. Далее до тех пор, пока первое множество не иссякнет выполняем процедуру обхода: для каждого элемента первого множества выводим его, после чего добавляем всех его потомков во второе множество. После того, как все элементы первого множества будут обработаны, назначаем второе множество первым, а пустое множество — новым вторым.
Решение при помощи слоёв удобно для вычисления минимальных расстояний, количества кратчайших путей или просто путей и подобных задач.
Решение при помощи очереди.
Воспользуемся деком из модуля collections, он позволяет эффективно добавлять элементы слева списка, а забирать — справа.
Такая структура данных называется очередью.
Добавим начальную вершину в очередь.
Множество посещённых вершин пока пусто.
Пока очередь не пуста будем выполнять простое действие: снимаем вершину с очереди, выводим её, добавляем в множество посещённых.
И добавляем всех её ещё не посещённых соседей в очередь.
Решение при помощи очереди хорошо обобщается на графы с разной стоимостью рёбер.
Например, поиск коротких путей в 0-1 графах (см. задачу ниже) делается из обычного обхода буквально в пару строчек.
Выполните обход графа в глубину начиная с этой вершины.
Сложность получившегося алгоритма должна быть O(∣V∣+∣E∣).
8
A B
B C
B D
B E
C E
D E
E F
G D
A
A
B
С
E
F
D
Подсказка (а также прочитать после решения)
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Здесь нужно делать всё также, как и для деревьев, только дополнительно нужно хранить множество посещённых вершин и не ходить в них повторно.
Есть три самых распространённых способа выполнения обхода в глубину.
Как обычно в разных случаях конкретный способ может быть удобнее благодаря некоторым бонусам.
Решение при помощи рекурсии:
Это самое простое с точки зрения реализации решение.
Стартуем с начальной вершины.
Проверяем, посещена ли текущая вершина. Если посещена, то заканчиваем обход.
Если ещё нет, то посещаем (выводим и добавляем в множество посещённых вершин), после чего рекурсивно применяем процедуру
ко всем ещё не посещённым соседям.
Само решение достаточно простое, и его легко модифицировать так, чтобы получать отметки времени входа и выхода.
В решении нужно не забыть увеличить максимальную глубину рекурсии.
Решение при помощи стека.
Добавляем начальную вершину в стек (в Python'е — в обычный список при помощи append),
а также в множество посещённых вершин.
Далее работаем в цикле пока стек не пуст:
снимаем вершину со стека (в Python'е — при помощи pop).
Проверяем, посещена ли она.
Если ещё нет, то посещаем (выводим и добавляем в множество посещённых вершин), после чего добавляем в стек всех ещё не посещённых соседей.
Решение удобно своей краткостью, простотой и эффективностью, однако его достаточно сложно дополнять фичами.
Решение при помощи стека и покраски вершин.
Будем обходить граф и попутно красить вершины.
Цвет вершины будем хранить в словаре.
Изначально все вершины белые — это значит, мы с этими вершинами ещё ни разу не сталкивались.
Будем использовать стек, в котором в каждый момент времени будет храниться путь из начальной вершины до текущей,
а также множество ещё необработанных соседей каждой вершины в стеке.
Кладём в стек пару из начальной вершины и множества её соседей, после чего красим её в серый цвет.
Серый цвет означает, что мы уже встречали эту вершину, но ещё не обошли в глубину всех её соседей.
Дальше пока стек не пуст выполняем:
Смотрим на вершину стека.
Если в множество соседей для обработки пусто,
то красим вершину в чёрный цвет (что означает, что все соседи данной вершины уже пройдены),
после чего удаляем её (вместе с уже пустым множеством её необработанных соседей) из стека.
Если же множество ещё непусто, то изымаем из него очередную вершину.
Если она белая, то красим её в серый и добавляем в стек её и множество её соседей. Иначе игнорируем её.
Такое решение удобно и для вычисления отметок весов (время входа — момент покраски в серый, времы выхода — в чёрный),
для классификации рёбер на древесные, прямые, обратные и перекрёстные.
В таком решении легко вывести путь из корня до текущей вершины (нужно просто пройти по стеку).
В таком решении удобно искать циклы: если при обработке множества необработанных соседей мы встретили серую вершину,
то тем самым нашли цикл, так как серые вершины — это в точности вершины в нашем стеке.
А ещё с помощью такого решения удобно делать топологическую сортировку.
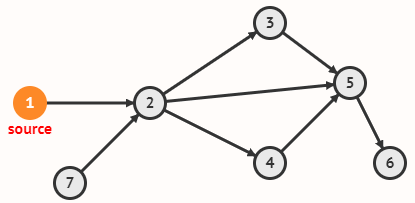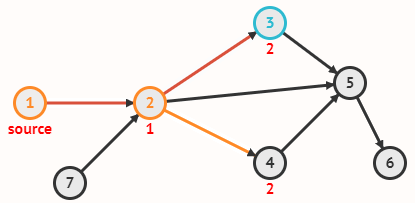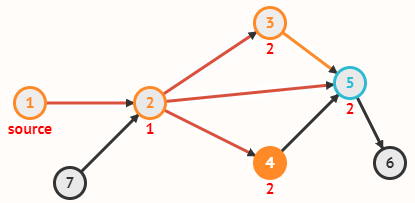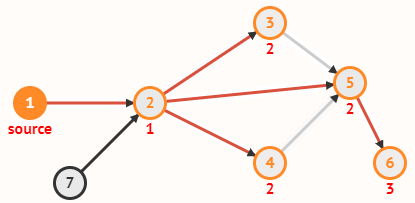
Дан ориентированный граф и отмечена одна из его вершин.
Для каждой вершины графа выведите длину минимального пути из отмеченной.
Если такого пути нет, то выведите -1.
Вершины должны выводиться в лексикографическом порядке.
Сложность получившегося алгоритма должна быть O(∣V∣+∣E∣).
Подсказка
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Здесь удобно сделать обход в ширину по слоям (см. подсказку к обходу в ширину).
При этом мы для каждого слоя будем в словаре сохранять его расстояние до начальной вершины.
Сложность получившегося алгоритма должна быть O(∣V∣+∣E∣).
8
A B
B C
B D
B E
C E
D E
E F
G D
1
3
A B
C D
E F
3
Подсказка
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Идея снова очень проста:
берём вершину и делаем из неё обход в ширину или в глубину.
Все посещённые вершины дают компоненту связности.
Дальше нужно брать ещё непосещённую вершину и повторять до тех пор, пока все вершины будут посещены.
Выполним обход в ширину начиная с этой вершины.
Рассмотрим множество рёбер, после прохода по которым мы попадали в новую вершину.
Они образуют корневое дерево с корнем в исходной вершине.
Выведите словарь parents этого корневого дерева.
Сложность получившегося алгоритма должна быть O(∣V∣+∣E∣).
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Достаточно легко модифицируется любой вариант обхода в ширину.
Каждый раз, когда мы "посещаем" вершину во время обхода в ширину, нужно добавить её предка в словарь.
Отдельно нужно добавить запись для корня (с ссылкой на Node).
Дан ориентированный граф и отмечена одна из его вершин V.
Далее перечисляются несколько вершин этого графа.
Для каждой вершины W выведите какой-нибудь из самых коротких путей из вершины V в вершину W, и -1 если такого пути нет.
Сложность подготовки должна быть O(∣V∣+∣E∣).
Сложность нахождения какого-либо из самых коротких путей после подготовки должна быть порядка длины этого пути.
8
A B
B C
B D
B E
C E
D E
E F
G D
A
3
B
F
G
A B
A B E F
-1
Подсказка
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Это — очень красивое применение дерева обхода в ширину.
Один из самых коротких путей всегда будет по дереву обхода в ширину, так уж оно устроено :)
Имея дерево обхода очень легко найти путь от него к корню, после чего обратить его.
Выполним обход в глубину начиная с этой вершины.
Рассмотрим множество рёбер, после прохода по которым мы попадали в новую вершину.
Они образуют корневое дерево с корнем в исходной вершине.
Выведите словарь parents этого корневого дерева.
Сложность получившегося алгоритма должна быть O(∣V∣+∣E∣).
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Достаточно легко модифицируется любой вариант обхода в глубину.
Каждый раз, когда мы "посещаем" вершину во время обхода в глубину, нужно добавить её предка в словарь.
Отдельно нужно добавить запись для корня (с ссылкой на Node).
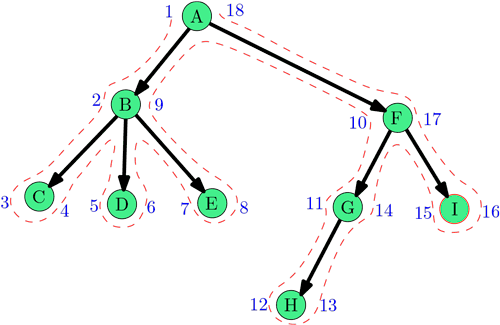
Метки времени — это натуральные числа от 1 до 2∣V∣.
Каждая вершина при обходе в глубину получает две метки: время начала обработки и время окончания,
причём все метки всех вершин различны.
Заведём счётчик времени.
Изначально счётчик равен нулю.
Каждый раз, когда мы переходим от одной вершины к другой мы прибавляем к счётчику единицу.
Время начала обработки — это значение счётчика в тот момент, когда мы «выводим рассматриваемую вершину».
Время окончания — это значение счётчика после того, как будет выполнен обход в глубину для всех сыновьих вершин.
Каждый раз, когда мы начинаем обход для какой-либо вершины, мы прибавляем 1 к счётчику.
Аналогично мы прибавляем 1 к счётчику после того, как закончили обход для данной вершины.
На картинке справа приведён обход в глубину дерева с отметками времени.
При работе с произвольным графом всё устроено очень похожим образом.
Только потребуется проверять, посещали ли мы эту вершину.
А также нужно стартовать новый обход и новое дерево, если в результате обхода посещены ещё не все вершины.
Нумерацию при этом нужно продолжать.
Если в графе есть цикл, то выведите 'YES' и вершины любого цикла.
В противном случае выведите 'NO'.
Сложность получившегося алгоритма должна быть O(∣V∣+∣E∣).
8
A B
B C
B D
B E
C E
D E
E F
G D
YES
B C E D
3
A B
B C
C D
NO
Подсказка
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
И эта задача решается при помощи обхода.
Выполняем обход в глубину или в ширину, сохраняя при этом дерево обхода (см. соответствующие задачи).
Как только очередное ребро смотрит в посещённую вершину — мы получили цикл.
Проще всего его получить пройдя от этих вершин до их наименьшего общего предка (или прямо до корня).
Дан ориентированный граф без циклов.
Необходимо вывести все его вершины в таком порядке,
чтобы из любой вершины с большим номером не существовало пути ни в какую вершину с м́еньшим номером.
Сложность получившегося алгоритма должна быть O(∣V∣+∣E∣) или O(log(∣V∣)⋅(∣V∣+∣E∣)).
8
A B
B C
B D
B E
C E
D E
E F
G D
G A B C D E F
Подсказка
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Если проставить метки времени при обходе в глубину, то после этого сделать топологическую сортировку уже очень-очень просто!