Цель машинного обучения — предсказать результат по входным данным без явного программирования всей логики.
Алгоритмы обучения (learning algorithms) делают предсказания или принимают решения не на основе строго статических программных команд, а на основе обучающей выборки (т.е. обучающих данных)
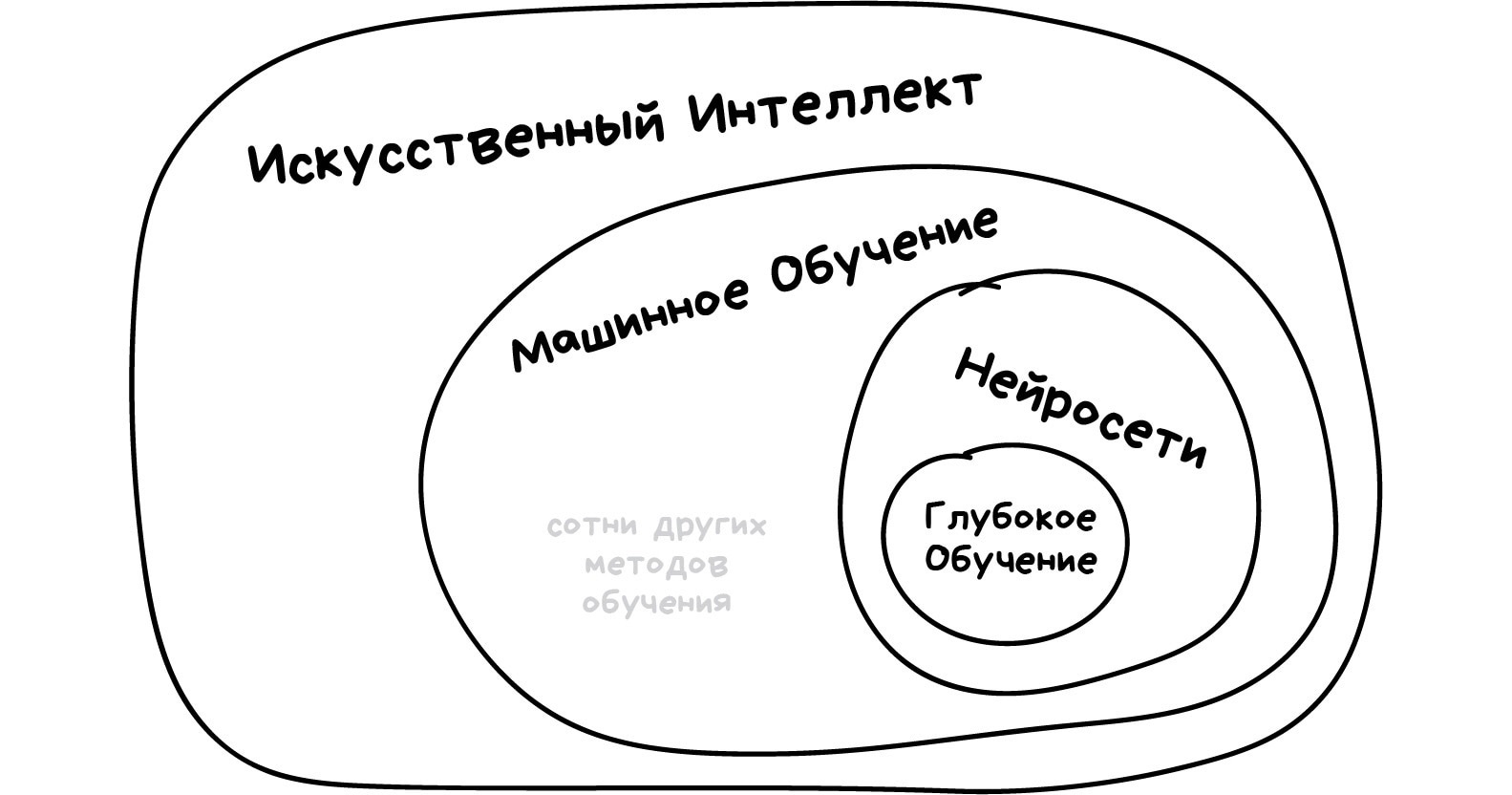
Искусственный интеллект — название всей области, как биология или химия.
Машинное обучение — это раздел искусственного интеллекта. Важный, но не единственный.
Нейросети — один из видов машинного обучения. Популярный, но есть и другие, не хуже.
Глубокое обучение — архитектура нейросетей, один из подходов к их построению и обучению. На практике сегодня мало кто отличает, где глубокие нейросети, а где не очень. Говорят название конкретной сети и всё.
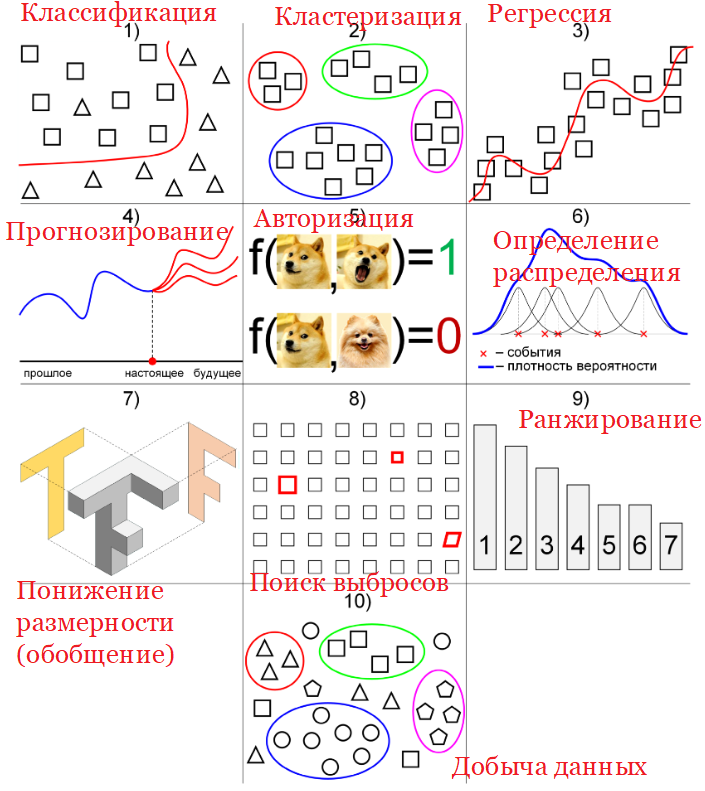
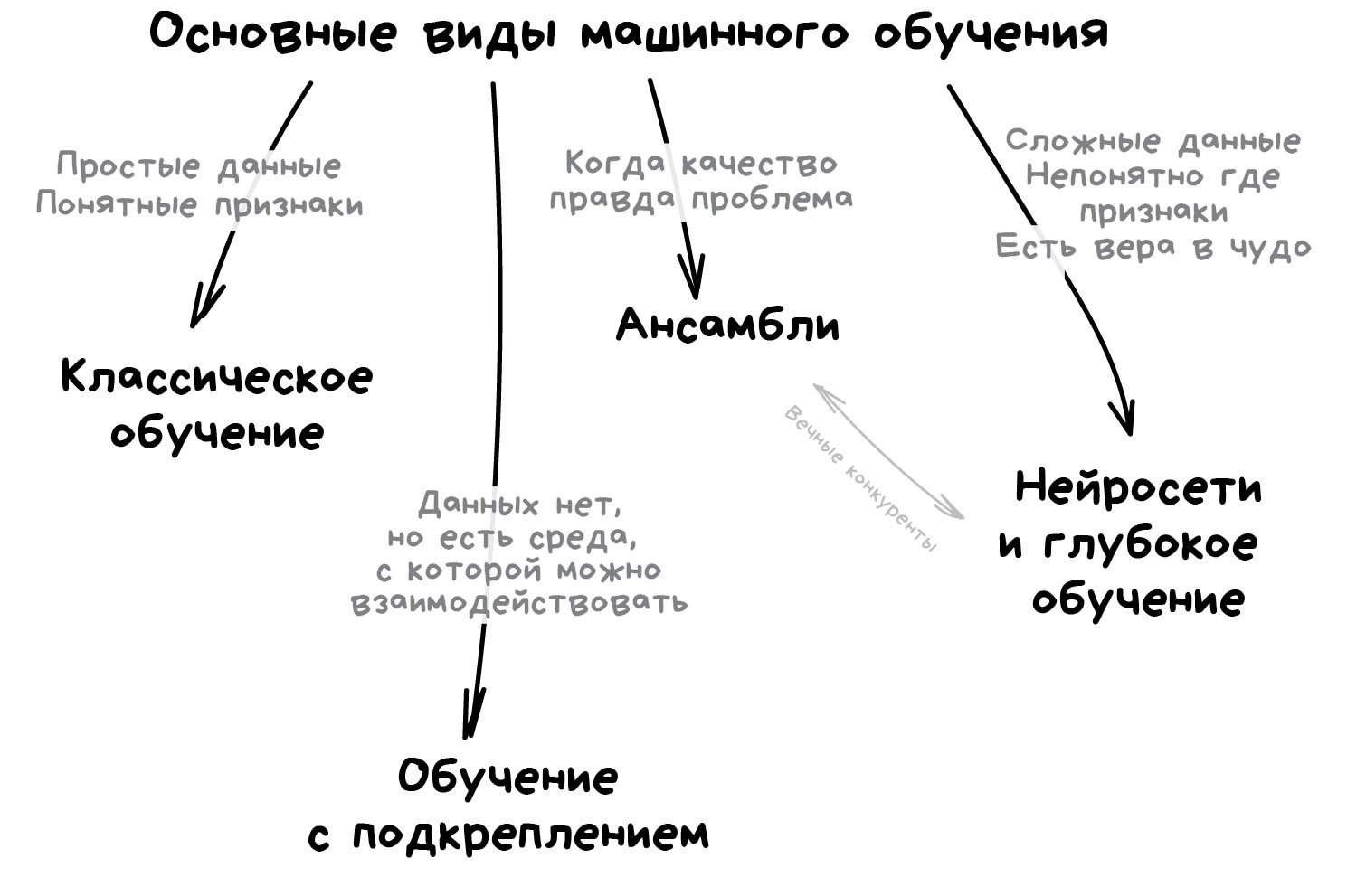
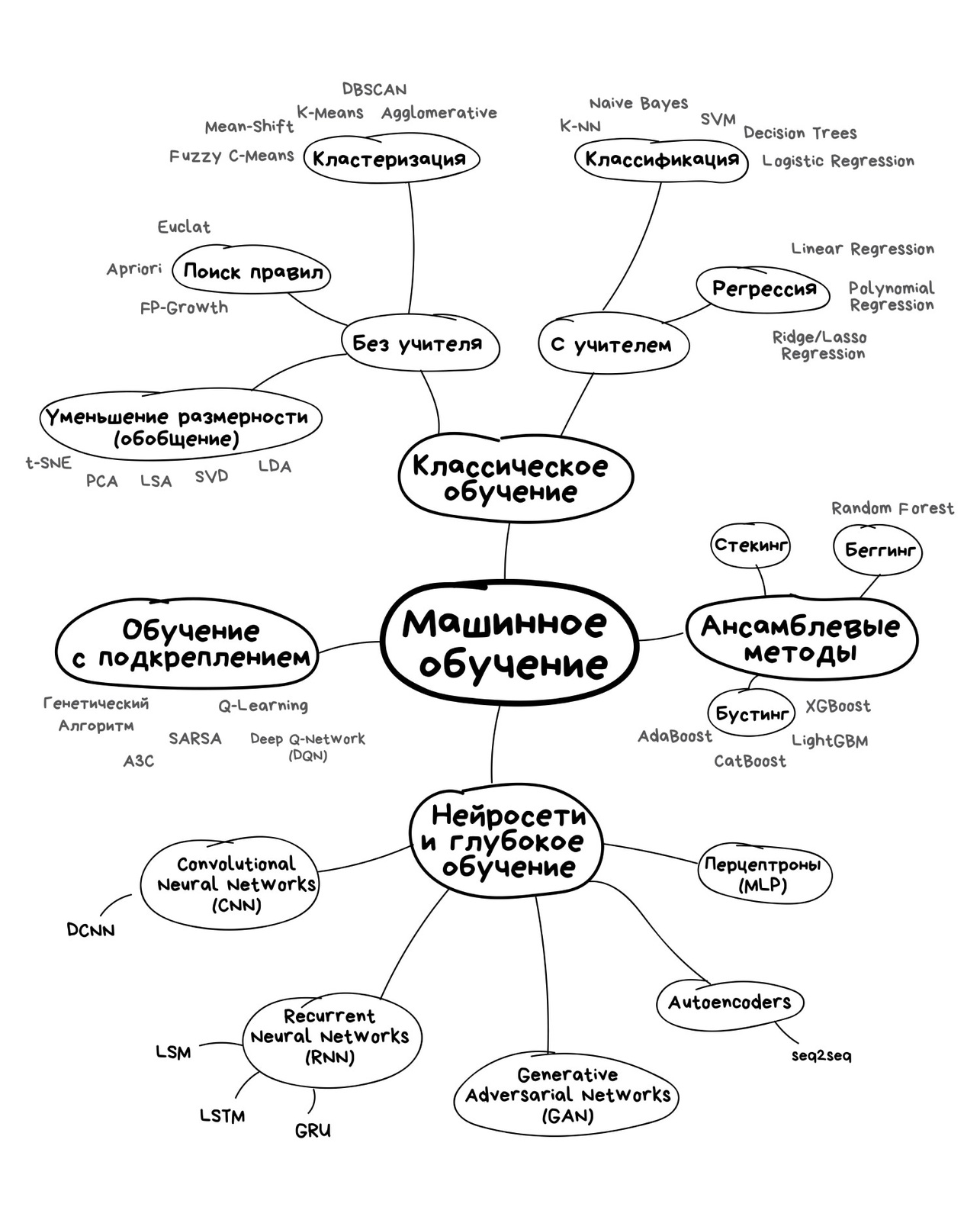
Методы машинного обучения разделяются по типам решаемых задач.
При этом ещё и возникают новые типы задач и даже целые новые дисциплины машинного обучения, например, добыча данных (data mining).
Классификация – разделение множества объектов или ситуаций на классы с помощью обучения
с учителем. Классифицировать объект – значит, указать номер, имя или метку класса, к которому
относится данный объект. Иногда требуется указать вероятность отношения объекта к классу. Например,
по обучающей выборке фотографий котов и собак научиться различать изображения котов и собак.
Кластеризация (сегментация) – разделение множества объектов или ситуаций на кластеры
с помощью обучения без учителя. Кластеризация (обучение без учителя) отличается от классификации
(обучения с учителем) тем, что перечень групп четко не задан и определяется в процессе работы
алгоритма, т.е. нет заранее определённых «правильных» ответов.
Регрессия – нахождение зависимости выходной переменной от одной или нескольких
независимых входных переменных с помощью обучения с учителем. В отличие он задач классификации,
которые разделяют объекты на дискретное количество классов, задачи регрессии находят зависимости
между непрерывными величинами. Например, нахождение зависимости между количеством съеденной пищи
и весом тела.
Прогнозирование – это предсказание во времени. Прогнозирование похоже либо на регрессию,
либо на классификацию в зависимости от данных задачи (непрерывные или дискретные данные),
но в отличие от регрессии и классификации всегда направлено в будущее. В прогнозировании данные
упорядочиваются по времени, которое является явным и ключевым параметром, а найденная зависимость
экстраполируется в будущее.
Идентификация. Идентификация и классификация многими ошибочно понимаются как синонимы.
Задача идентификации исторически возникла из задачи классификации, когда вместо определения класса
объекта потребовалось уметь определять, обладает объект требуемым свойством или нет.
Особенностью задачи идентификации является то, что все объекты принадлежат одному классу,
и не существует возможности разделить класс на подклассы, т.е. сделать состоятельную выборку
из класса, которая не будет обладать требуемым свойством. Если требуется определить человека по
фотографии его лица, причём множество запомненных в базе людей постоянно меняется и появляются люди,
которых не было в обучающем множестве, то это задача идентификации, которая не сводится к задаче
классификации.
Восстановление плотности распределения вероятности по набору данных (kernel density estimate).
Данная задача является центральной проблемой математической статистики. Математическая статистика
решает обратные задачи: по результату эксперимента определяет свойства закона распределения.
Исчерпывающей характеристикой закона распределения является плотность распределения вероятностей.
Например, известен возраст людей, берущих кредит в банке, требуется найти плотность распределения
вероятности возрастов заёмщиков.
Понижение размерности данных и их визуализация. Является частным случаем кластеризации.
Каждый объект может быть представлен в виде многомерного вектора признаков, но нужно получить более компактное признаковое описание объекта.
Понижение размерности может помочь другим методам путём
устранения избыточных данных. Используется при разведочном анализе и для устранения
«проклятия размерности», когда данные быстро становятся разреженными при увеличении размерности
пространства признаков. Например, дан список документов на человеческом языке,
требуется найти документы с похожими темами.
Одноклассовая классификация и выявление новизны. Или задача поиска аномалий, выбросов,
которые не относятся ни к одному кластеру. Нахождение объектов, которые отличаются по своим
свойствам от объектов обучающей выборки. Является задачей обучения без учителя. Например,
обнаружение инородных предметов (кости, камни, кусочки упаковки) в продуктах питания при их
сканировании рентгеновским сканером при неразрушающем контроле качества продукции, обнаружение
подозрительных банковских операций, обнаружение хакерской атаки, медицинская диагностика и т.д.
Построение ранговых зависимостей. Ранжирование – это процедура упорядочения объектов
по степени выраженности какого-либо качества в порядке убывания этого качества.
Задачами ранжирования являются: сортировка веб-страниц согласно заданному поисковому запросу,
персонализация новостной ленты, рекомендации товаров (видео, музыки), адресная реклама.
Добыча данных (data mining) – совокупность
методов обнаружения в данных ранее неизвестных, нетривиальных знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Интеллектуальный анализ данных и машинное обучение имеют различные цели:
машинное обучение прогнозирует на основе известных свойств, полученных от обучающей выборки,
а интеллектуальный анализ данных фокусируется на добыче новых ранее неизвестных зависимостей
в данных.
Итак, если мы хотим обучить машину, нам нужны три вещи:
1. Данные.
Хотим определять спам — нужны примеры спам-писем, предсказывать курс акций — нужна история цен, узнать интересы пользователя — нужны его лайки
или
посты.
Данных нужно как можно больше. Десятки тысяч примеров — это самый злой минимум для отчаянных.
Данные собирают как могут. Кто-то вручную — получается дольше, меньше, зато без ошибок.
Кто-то автоматически — просто сливает машине всё, что нашлось, и верит в лучшее.
Самые хитрые, типа гугла, используют своих же пользователей для бесплатной разметки. Вспомните ReCaptcha, которая иногда требует «найти на фотографии все дорожные знаки» — это оно и есть.
За хорошими наборами данных (датасетами) идёт большая охота. Крупные компании, бывает, раскрывают свои алгоритмы, но датасеты — крайне редко.
2. Признаки.
Мы называем их фичами (features). Фичи, свойства, характеристики, признаки — ими могут
быть пробег автомобиля, пол пользователя, цена акций, даже счетчик частоты появления слова в тексте может быть фичей.
Машина должна знать, на что ей конкретно смотреть. Хорошо, когда данные просто лежат в табличках — названия их колонок и есть фичи. А если у нас сто гигабайт картинок с котами? Когда признаков много, модель работает медленно и неэффективно. Зачастую отбор правильных фич занимает больше времени, чем всё остальное обучение. Но бывают и обратные ситуации, когда кожаный мешок сам решает отобрать только «правильные» на его взгляд признаки и вносит в модель субъективность — она начинает дико врать.
3. Алгоритм.
Одну задачу можно решить разными методами примерно всегда. От выбора метода зависит точность, скорость работы и размер готовой модели.
Но есть один нюанс: если данные — полный треш, то даже самый лучший алгоритм не поможет.
Не зацикливайтесь на процентах, лучше соберите побольше данных.
Термин «машинное обучение» в 1959 году ввёл исследователь в области компьютерных игр Артур Самуэль и определил его как «процесс, в результате которого машина (компьютер) способна показывать поведение, которое в неё не было явно заложено (запрограммировано)».
Игру в шашки, изобретенную Самуэлем в 1952 году, принято считать первой программой, способной самообучаться.
Самуэль выбрал шашки, потому что правила игры относительно просты, но имеют развитую стратегию.
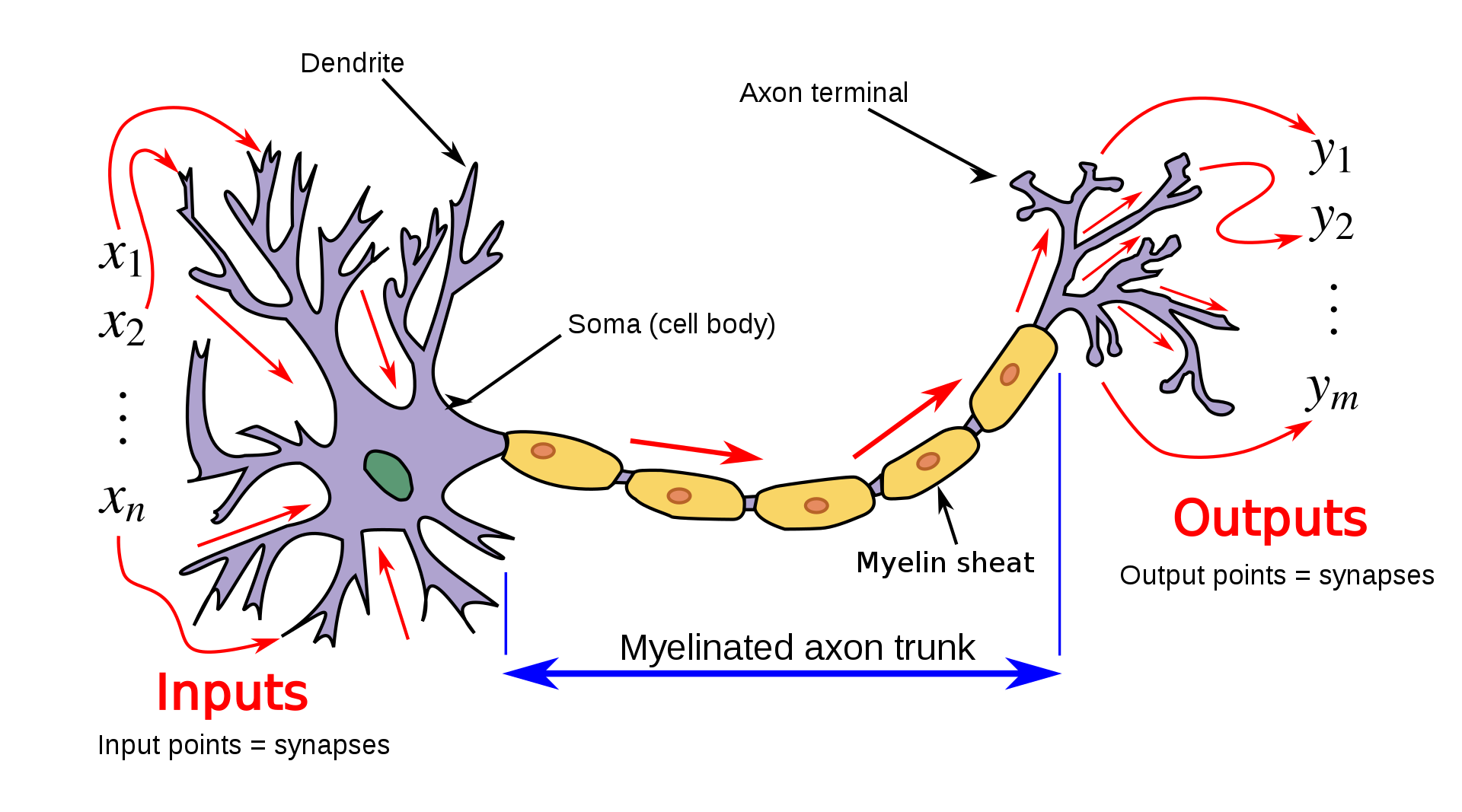
Искусственная нейронная сеть (ИНС) – это математическая модель, а также её программное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей, т.е. сетей нервных клеток живого организма.
Первой попыткой построить ИНС по принципу функционирования мозга были нейронные сети Уоррена Мак-Каллока и Уолтера Питтса, описанные в статье 1943 года.
Это была яркая идея, учитывая то, что электрическая природа сигналов нейронов будет продемонстрирована только спустя семь лет в конце 1950-х годов.
Математическая модель сети Мак-Каллока и Питтса из искусственных нейронов теоретически могла выполнять числовые или логические операции любой сложности.
Современный интерес к нейронным сетям возрос после того, как вычислительные мощности дошли до уровня, когда обучение нейронной сети стало занимать приемлимое
время, годам к 2010. Значительную часть математики нейронных сетей придумали ещё к 1990 году.
Любая нейросеть — это набор нейронов и связей между ними.
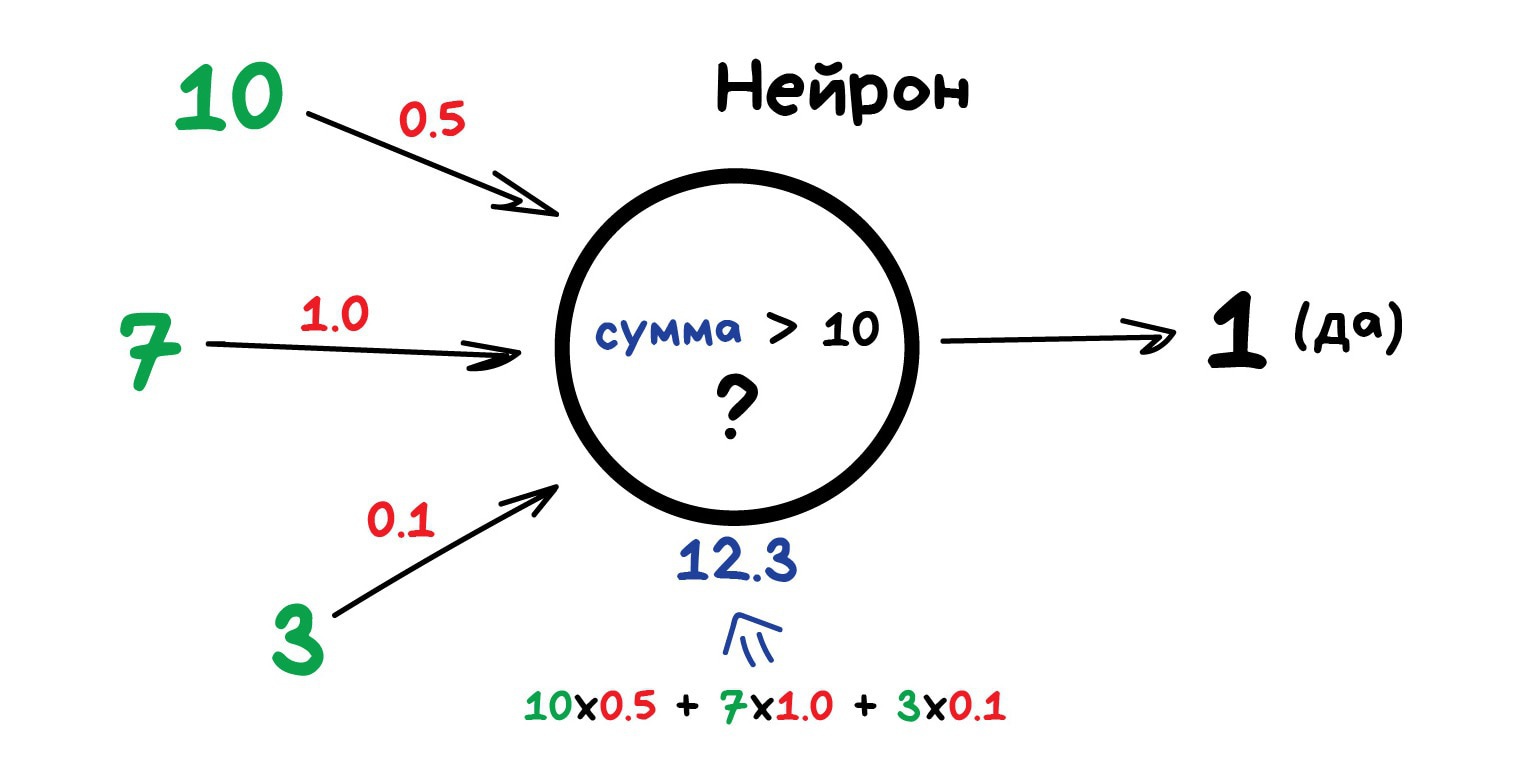
Нейрон лучше всего представлять просто как функцию с кучей входов и одним выходом.
Задача нейрона — взять числа со своих входов, выполнить над ними функцию и отдать результат на выход.
Простой пример полезного нейрона: просуммировать все цифры со входов, и если их сумма больше N — выдать на выход единицу, иначе — ноль.
Связи — это каналы, через которые нейроны шлют друг другу циферки. У каждой связи есть свой вес — её единственный параметр, который можно условно представить как прочность связи. Когда через связь с весом 0.5 проходит число 10, оно превращается в 5. Сам нейрон не разбирается, что к нему пришло и суммирует всё подряд — вот веса и нужны, чтобы управлять на какие входы нейрон должен реагировать, а на какие нет.
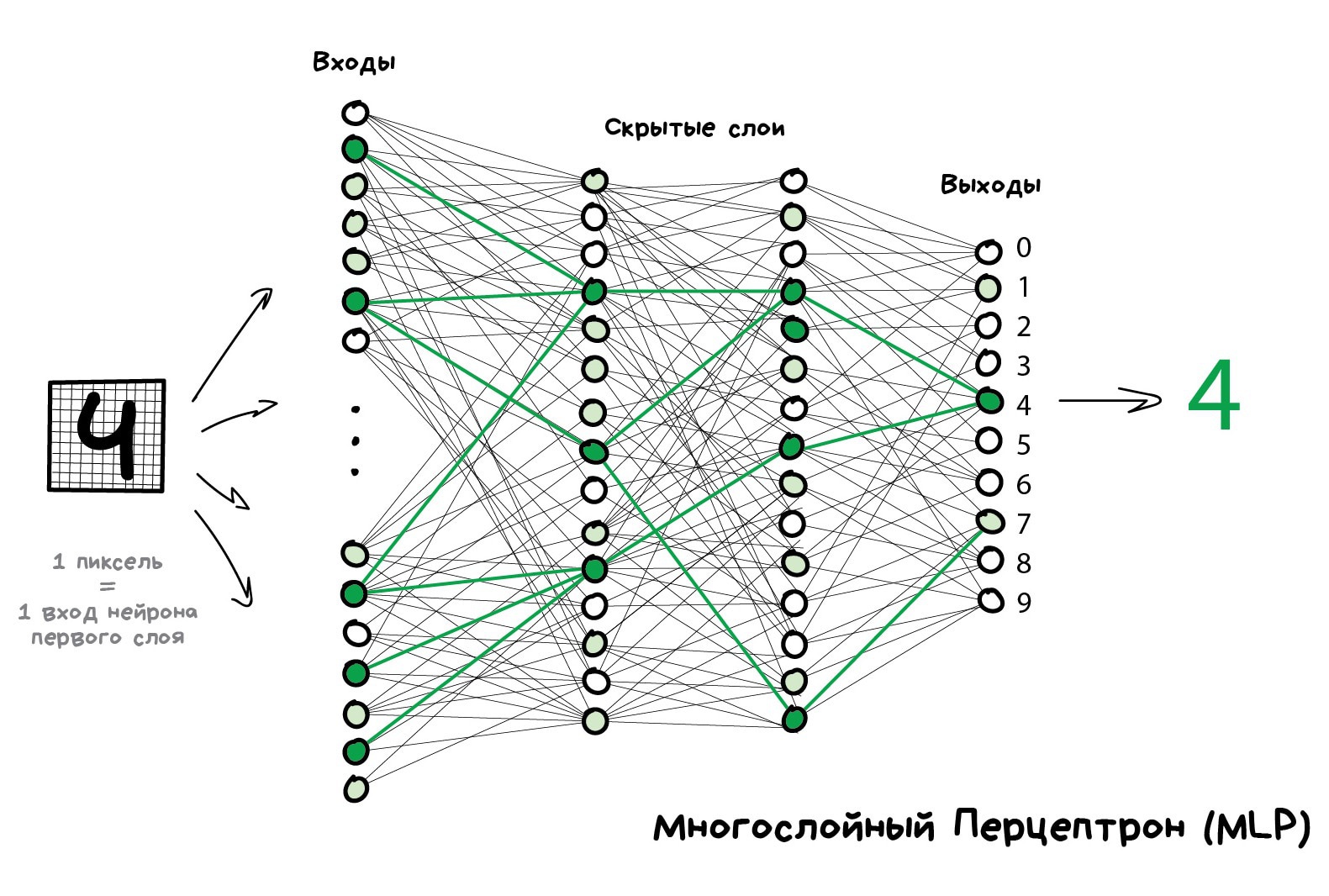
Чтобы сеть не превратилась в анархию, нейроны решили связывать не как захочется, а по слоям. Внутри одного слоя нейроны никак не связаны, но соединены с нейронами следующего и предыдущего слоя. Данные в такой сети идут строго в одном направлении — от входов первого слоя к выходам последнего. Такие сети называются feed forward
Если нафигачить достаточное количество слоёв и правильно расставить веса в такой сети, получается следующее — подав на вход, скажем, изображение написанной от руки цифры 4, чёрные пиксели активируют связанные с ними нейроны, те активируют следующие слои, и так далее и далее, пока в итоге не загорится самый выход, отвечающий за четвёрку. Результат достигнут.
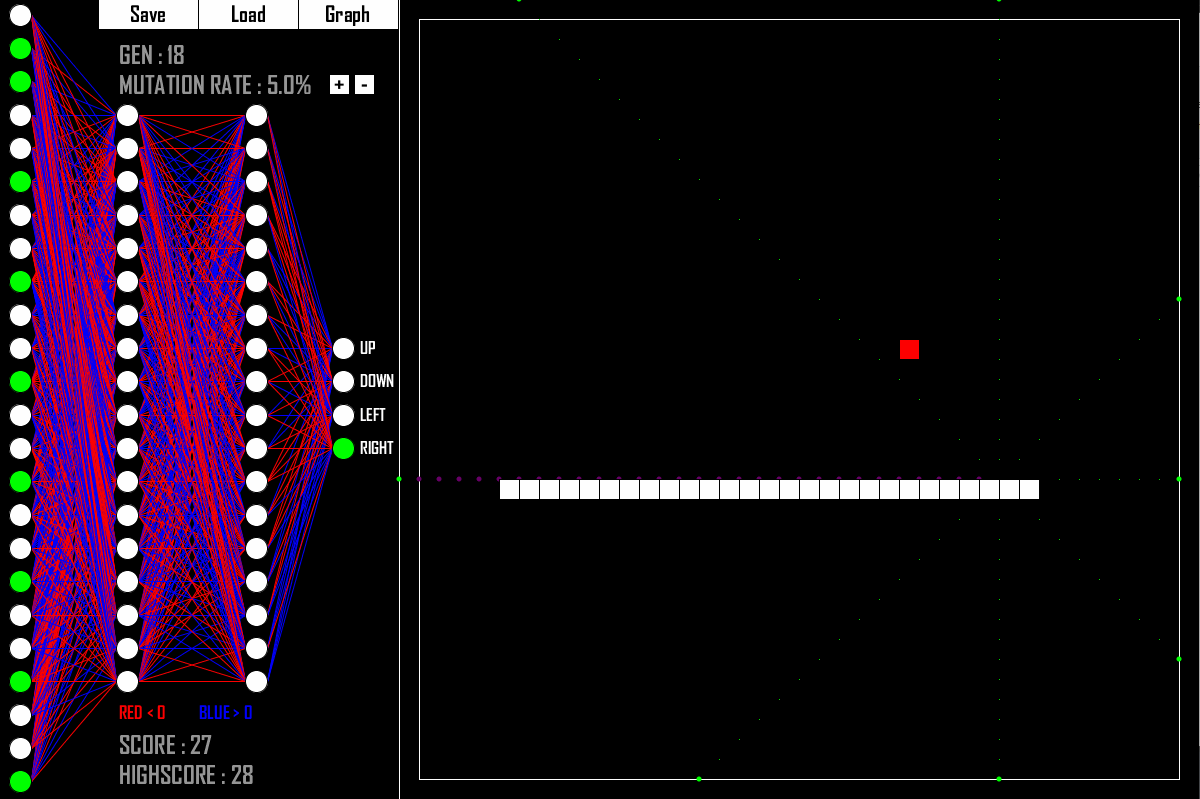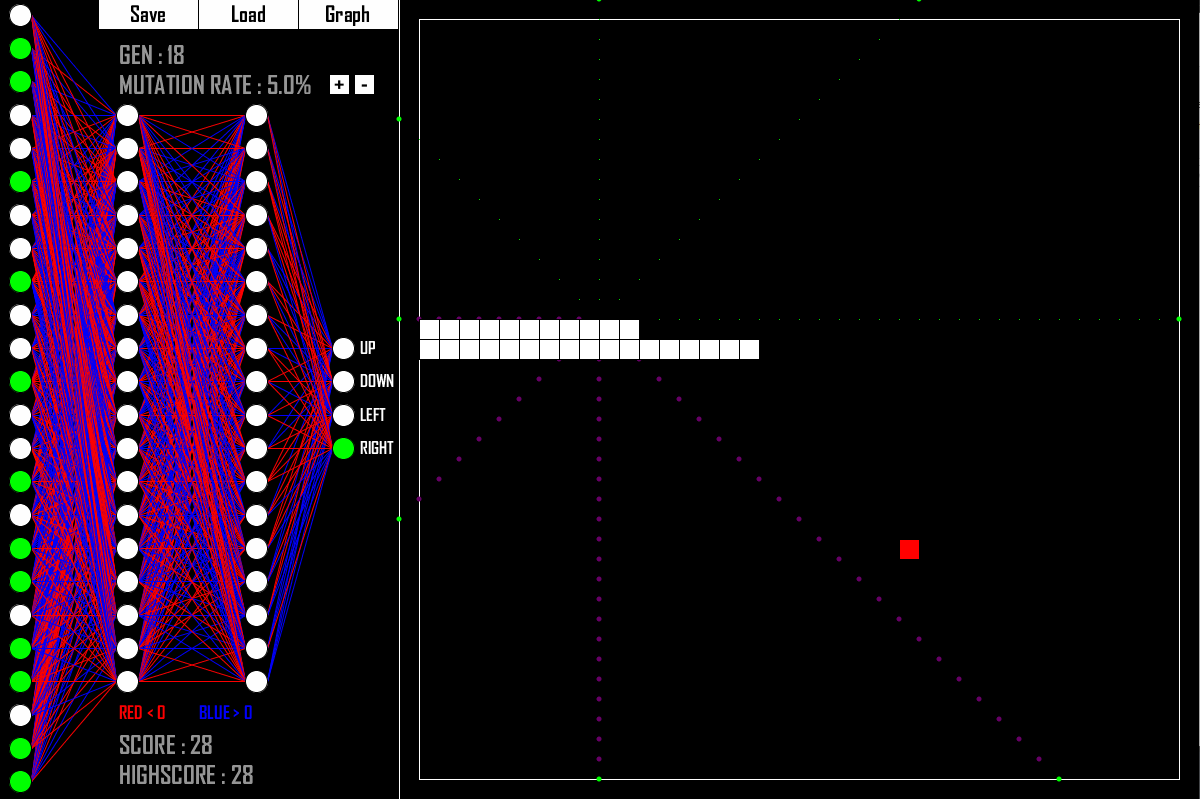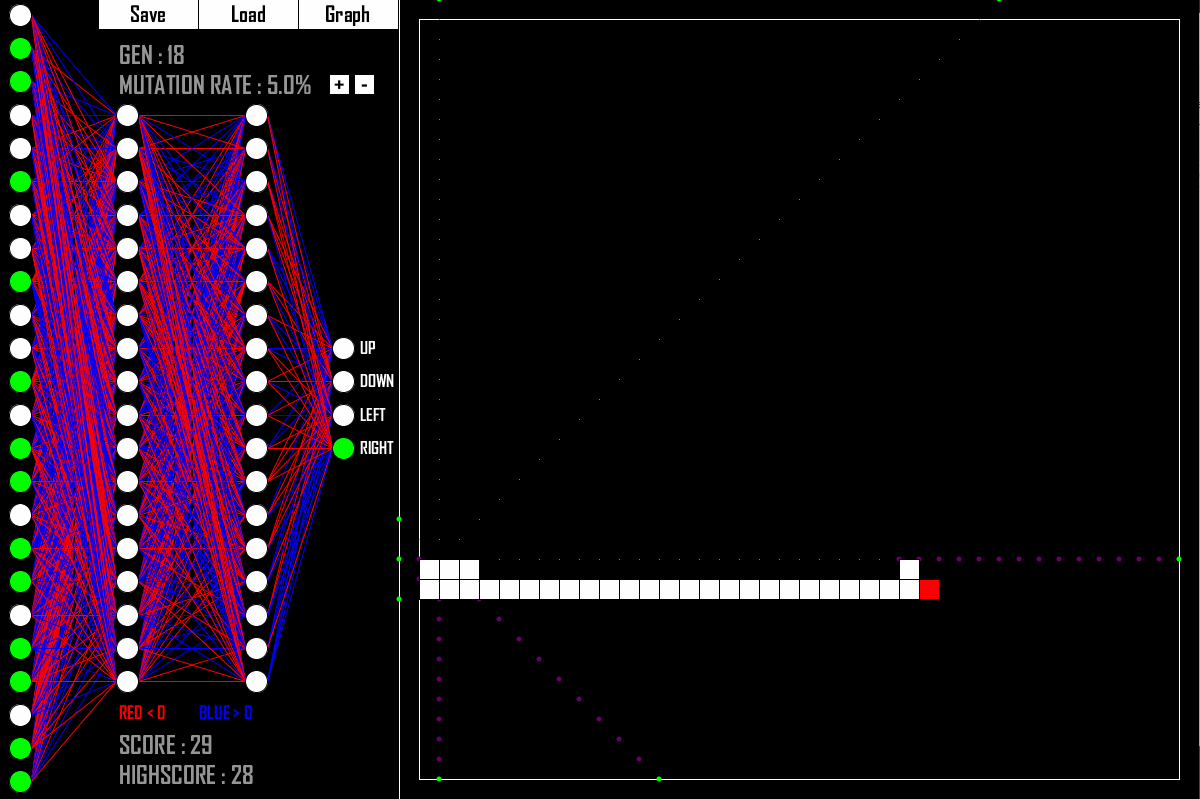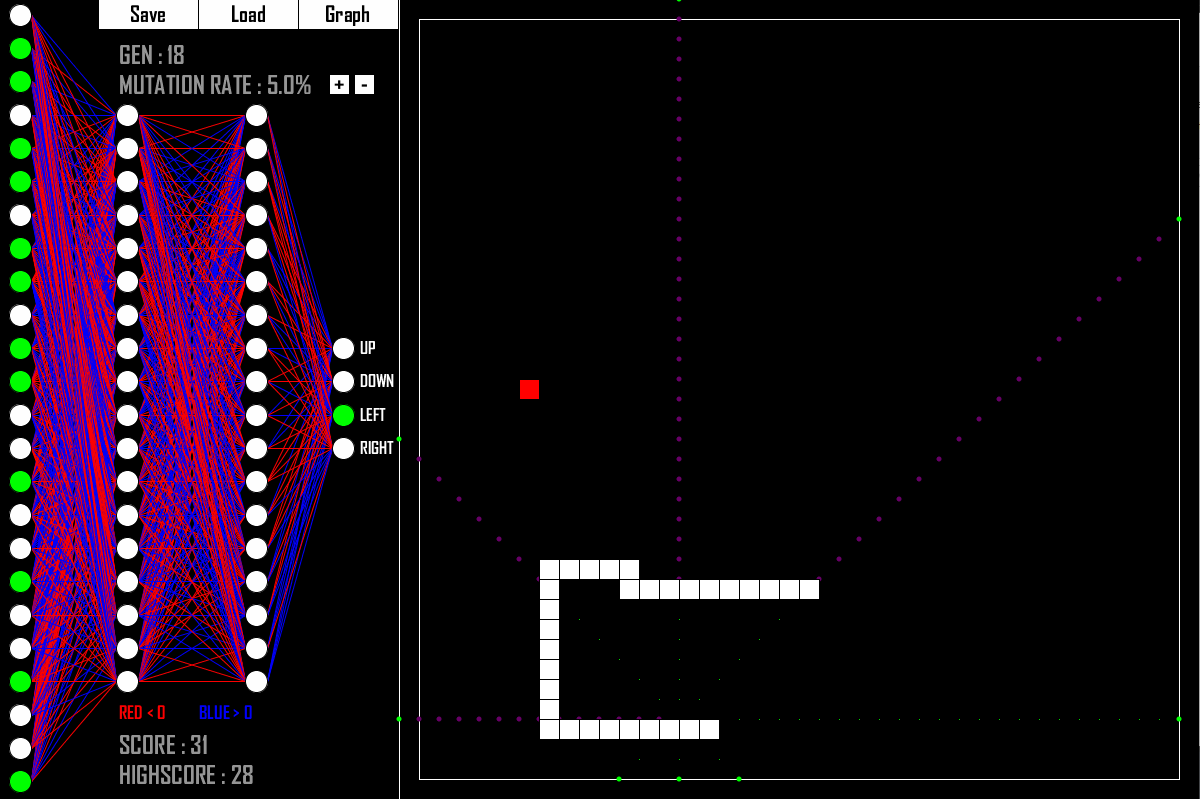
Вот как это выглядит в действии для управления змейкой:
В реальном программировании, естественно, никаких нейронов и связей не пишут, всё представляют матрицами и считают матричными произведениями, потому что нужна скорость.
Когда мы построили сеть, наша задача правильно расставить веса, чтобы нейроны реагировали на нужные сигналы. Тут нужно вспомнить, что у нас же есть данные — примеры «входов» и правильных «выходов».
Будем показывать нейросети рисунок той же цифры 4 и говорить «подстрой свои веса так, чтобы на твоём выходе при таком входе всегда загоралась четвёрка».
Сначала все веса просто расставлены случайно, мы показываем сети цифру, она выдаёт какой-то случайный ответ (весов-то нет), а мы сравниваем, насколько результат отличается от нужного нам. Затем идём по сети в обратном направлении, от выходов ко входам, и говорим каждому нейрону — так, ты вот тут зачем-то активировался, из-за тебя всё пошло не так, давай ты будешь чуть меньше реагировать на вот эту связь и чуть больше на вон ту, ок?
Через тысяч сто таких циклов «прогнали-проверили-наказали» есть надежда, что веса в сети откорректируются так, как мы хотели. Научно этот подход называется Backpropagation или «Метод обратного распространения ошибки». Забавно то, что чтобы открыть этот метод понадобилось двадцать лет. До него нейросети обучали как могли.
В реальном программировании используется метод обратного распространения ошибки.
Но там — куча матана, линейной алгебры, производных и всякого такого.
Но есть метод для обучения, который всего этого не требует — генетический алгоритм.
Основная фишка алгоритма — скрещивание (комбинирование) и мутации.
Как несложно догадаться идея алгоритма наглым образом взята у природы.
Так вот, путем перебора и самое главное отбора получается правильная «комбинация».
Итак, нейронная сеть у нас задаётся кучей чисел.
Выпишем их в ряд и назовём геномом.
Для каждой сети мы должны уметь оценить числом, «насколько она хороша».
Это число часто называется fitness.
Теперь шаги алгоритма.
Создать популяцию из случайных сетей;
Посчитать «годность» каждой сети;
Проверить, не подходят ли по качеству эти лучшие?
Добавить в новое поколение:
Несколько самых годных сетей;
Несколько мутантов, полученных из самых годных;
Несколько сетей, полученных «скрещиванием» (crossover);
Ещё какой-нибудь магии;
Повторить п.2.
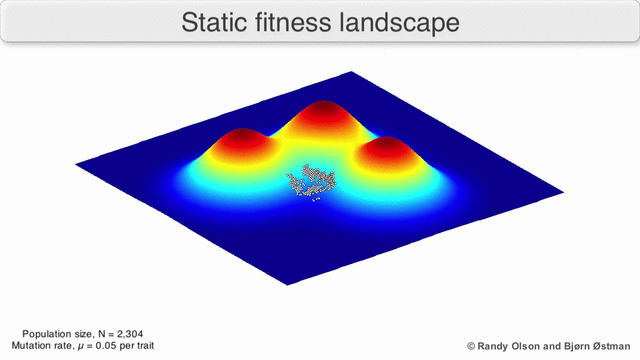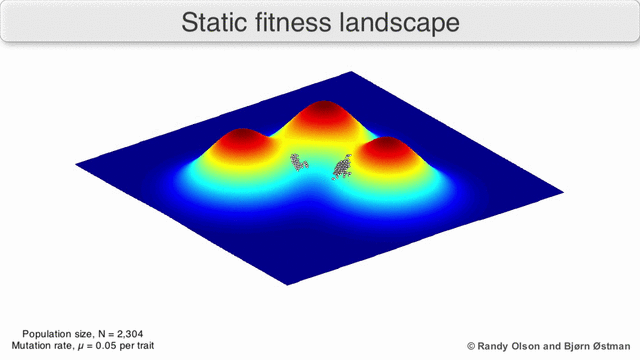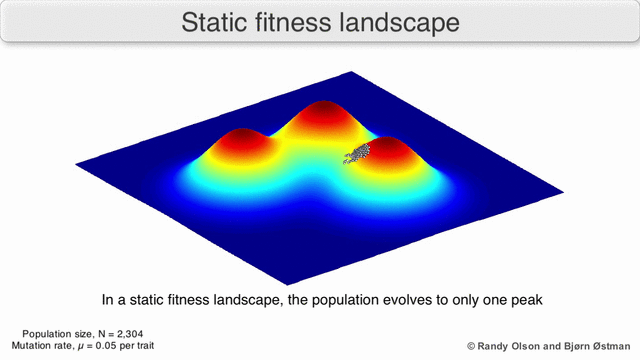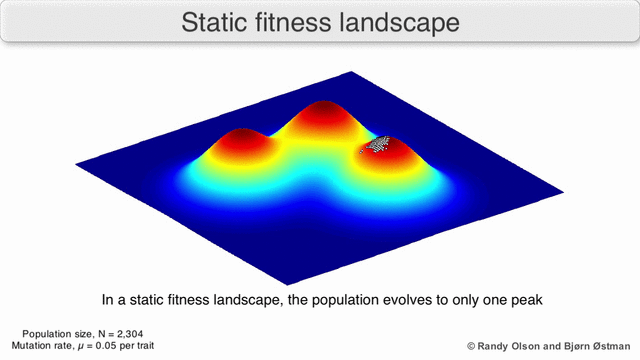
Если бы коэффициентов было всего два, то можно было бы нарисовать трёхмерный график зависимости годности от параметров.
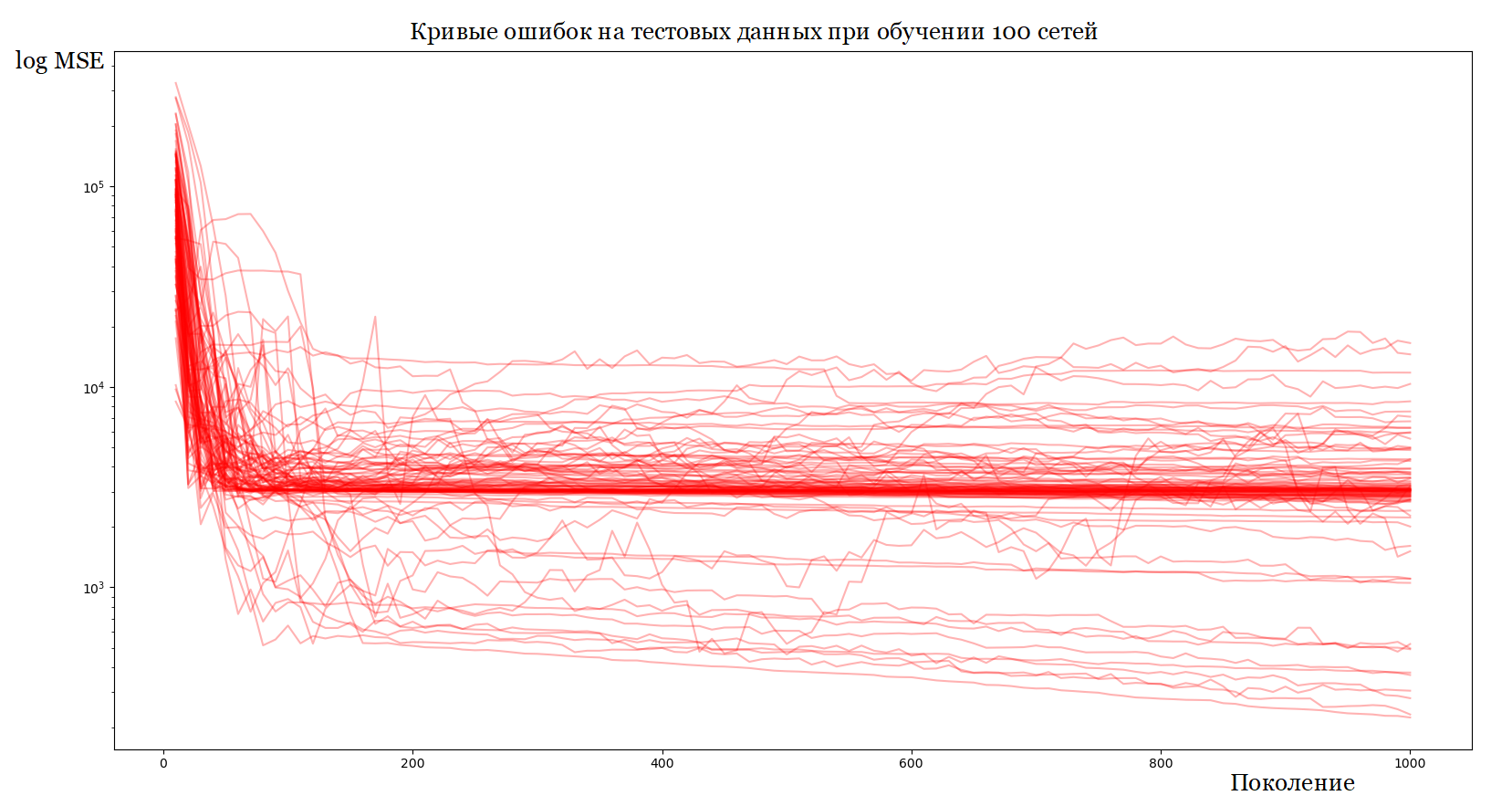
Результат работы генетического алгоритма выглядел бы как-то так:
В реальной жизни коэффициентов от сотен до миллионов, и построить такой график невозможно.
Что ещё хуже, у этого графика очень много «пиков», ведь любые перестановки нейронов в одном слое не меняют результат работы сети.
То есть мы бы хотели найти максимум в безумном многомерном пространстве, покрытым бесчисленным количеством пиков (ох, какие там факториалы!).
# Часть первая: сеть из одного нейрона и её обвязка
Нейронная сеть из одного нейрона может научиться делать линейную регрессию — находить такую зависимость y=ax+b, которая лучше всего
описывает данные.
Так как формула для перевода градусов Цельсия в Фаренгейты имеет в точности такой вид, то одиночный нейрон должен отлично учиться это делать.
Чтобы обучать и использовать нейронные сети, нужно сначала подготовить вспомогательные функции.
Общий план работ:
celsius_to_fahrenheit — эта фукнция потребуется для создания данных для обучения. Она даёт точный ответ;
gen_dataset — эта функция создаст нам данные для обучения: набор вопросов и правильных ответов на них;
mean_squared_error — эта функция посчитает, насколько набор ответов нейронной сети далёк от правильного;
Класс Network — это и есть нейронная сеть. Он хранит в себе коэффициенты нейронной сети и имеет методы для взаимодействия с сетью:
Network.__init__ — создаёт либо случайную нейронную сеть, либо сеть с заданными параметрами;
Network.__repr__ — выдаёт описание сети строчкой, чтобы было удобно пересоздать её в коде;
Network.predict — выдаёт предсказание сети по переданным данным;
Network.score — берёт набор данных (вопросы и ответы), для каждого вопроса предсказывает ответ и сравнивает с правильным. Возвращает
суммарную «оценку» качества предсказания;
Network.mutate — создаёт новую нейронную сеть, немного мутируя старую;
run_evolution — эта функция создат популяцию нейронных сетей и будет контролировать их эволюцию.
(если пишете на другом языке, то меняйте всё в соответствии с языком)
Начнём так, чтобы не перетрудиться сразу.
Напишите функцию celsius_to_fahrenheit, которая берёт температуру в градусах Цельсия и возвращает в градусах Фаренгейта.
Формулу посмотрите в Википедии, если тестов ниже вам не хватит :)
Напишите функцию gen_dataset, с единственным параметром: size — размер обучающей выборки.
Функция должна возвращать два массива, которые традиционно называются x_train и y_train.
x_train — набор случайных чисел на отрезке от −100 до +400 (random.uniform поможет) длины size.
y_train — набор «ответов» (результатов перевод из Цельсия в Фаренгейты) для каждого вопроса.
Напишите функцию mean_squared_error, которая берёт список правильных ответов y_true и список предсказаний y_pred и
по ним вычисляет средний квадрат ошибки.
Если мы обозначим правильные ответы через t1,t2,…,tn, а предсказания — через p1,p2,…,pn, то функция должна вернуть
MSE=ni=1∑n(ti−pi)2=n(t1−p1)2+(t2−p2)2+…+(tn−pn)2.
Создайте класс Network с констуктором и фукцией для вывода.
В питоне это «волшебные» методы __init__ и __repr__.
В C++ это констуктор и перегрузка оператора ostream& operator<<.
В javascript конструктор и метод toString.
В rust конструктор — это реализация метода pub fn new, а вывод — реализация трейта std::fmt::Display.
Если параметры для создания сети не переданы, то в качестве параметров должны быть выбраны случайные числа на отрезке [−1,1].
На вход даётся либо два числа, либо строка random.
Создайте экземляр сети либо с данными параметрами, либо со случайными.
Реализуйте метод predict.
Так как нейрон всего один и функция активации у него тождественная, то нейронная сеть должна на входе x выдавать ax+b, где a и b — коэффициенты
нейронной сети.
Реализуйте метод score для оценки сети.
Метод принимает на вход список запросов x_test, список правильных ответов y_true.
Для каждого запроса необходимо «предсказать» ответ.
После чего вернуть средний квадрат ошибки.
В первой строчке даются два действительных числа — параметры сети.
Во второй — число запросов.
В третьей — список запросов.
В четвёртой — список ответов.
Реализуйте метод mutate, который создаёт новую сеть из исходной при помощи мутации.
У метода должно быть два параметра: p — вероятность мутации, mx — максимальная величина мутации.
Метод должен создать новую нейронную сеть, каждый коэффициент которой с вероятностью p изменён на случайное число от −mx до mx.
В первой строчке параметры сети.
Во второй строчке три числа: вероятность 0≤p≤1, максимальное изменение −1000≤mx≤1000 и необходимое число клонов.
Реализуйте функцию run_evolution, которая будет управлять эволюцией.
Параметры функции:
population — начальная популяция;
epochs — количество смен эпох, которые нужно провести;
x_train и y_train — данные для обучения;
p и mx — параметры для мутаций;
На вход в первой строчке даётся число n — количество поколений, которые нужно провести.
Во второй строчке два числа — параметры мутаций: вероятность 0≤p≤1, максимальное изменение −1000≤mx≤1000.
Для того, чтобы сделать нечто с вероятностью p достаточно сравнить случайное число от 0 до 1 с p (см. функцию random.random).
Создайте популяцию из 50 случайных сетей, тестовые данные из 10 запросов (см. задачу B, gen_dataset) и выполните n поколений отбора.
Выведите лучшую из сетей и её MSE (средний квадрат ошибки) в каждом из поколений.
На вход даются два числа n и k: число запросов для обучения и число запросов для тестирования.
Затем идёт строка из n входов и строка из n ответов к ним.
После этого идёт строка из k тестов.
Обучите нейронную сеть в течение 2 секунды и предскажите ответы для каждого из тестов.
Отсечку по времени можно делать так:
from time import time
start = time()
while time() - start < 1:
...
Если сеть не проходит тесты, то придумывайте, как за две секунды достить лучшего результата обучения.
# Часть вторая: сети прямого распространения сигнала
Для упрощения модели в сетях прямого распространения сигнала (feed forward) нейроны связывают по слоям.
Внутри одного слоя нейроны никак не связаны, но соединены с нейронами следующего и предыдущего слоя.
Данные в такой сети идут строго в одном направлении — от входов первого слоя к выходам последнего.
Обычно веса и смещения (свободные коэффициенты) хранят в виде набора матриц и векторов.
А для вычислений испольуют матричные операции.
Если вы понимаете, что всё это значит, то можете реализовывать именно так.
Для упрощения жизни (и использования генетического алгоритма) будем использовать немного нетрадиционную систему для хранения параметров и весов сети.
Во-первых, будем хранить все коэффициенты в одном длинном-длинном массиве в атрибуте coefs.
Во-вторых, не будем особо различать входы, выходы и скрытые слои.
В атрибуте layer_sizes будем хранить число входов/нейронов/выходов в каждом слое.
Например, для сети из одного входа и одного нейрона размеры слоёв — layer_sizes = [1, 1].
Для сети на картинке выше layer_sizes = [3, 4, 2].
Таким образом у нашей сети число входов всегда равно layer_sizes[0], а число выходов — layer_sizes[-1].
Итак, структуру слоёв храним в атрибуте layer_sizes, а сами коэффициенты — в атрибуте coefs.
Для примера пронумеруем все коэффициенты сети со слоями layer_sizes = [3, 2, 3]:
Если слоёв больше, то будем продолжать их нумеровать в том же духе:
от слоя к слою;
в рамках одного слоя от «верхнего» нейрона к «нижнему»;
в камках одного нейрона от «верхнего» входящего нейрона предыдущего слоя к «нижнему», а после коэффициент для смещения.
Пусть layer_sizes=[l1,l2,…,ln].
Посчитаем, сколько нам нужно коэффициентов для нашей сети.
Слоёв в нашей сети n, а переходов из слоя в слой — n−1.
Если в одном слое a входов/нейронов, а в следующем — b, то для каждого из b нейронов требуется a весов и 1 число для смещения.
То есть получается (a+1)b коэффициентов.
Для всей сети тогда потребуется
(l1+1)l2+(l2+1)l+…+(ln−1+1)ln.
В качестве примера мы будем переводить сразу две температуры в градусах Цельсия в Фаренгейты.
При этом будем обучать сеть со структурой layer_sizes = [2, 3, 2] — это больше, чем требуется для этой задачи.
Но сеть-то про это не знает!
Чтобы начать работать с такой универсальной структурой сети нам нужно выполнить следующие доработки:
gen_dataset — теперь одна единица данных — это не число, а список. То есть функция должна возвращать список x_train, в
котором size списков с данными, а также список x_train, в
котором size списков с ответами;
mean_squared_error — тоже должна принимать список списков и считать более сложную штуку;
Network — в классе должны храниться атрибуты layer_sizes с размером слоёв и coefs с коэффициентами;
Network.__init__ — должен принимать структур сети (обязательно) и веса (необязательно). Если веса не переданы, то иницировать случайные веса
в соответствии со структурой;
Network.__repr__ — теперь нужно выдавать представление со структурой и весами;
Network.predict — теперь должен выдавать ответ для списка входных данных вычисляя результаты послойно;
Network.score — здесь тоже нужно перейки к спискам списков;
Network.mutate — здесь мы мутируем весь список коэффициентов coefs;
run_evolution — нужно будет внести соответствующие правки.
Напишите функцию gen_dataset, с двумя параметрами: размер обучающей выборки и количество температур в одном запросе.
Функция должна возвращать два массива, которые традиционно называются x_train и y_train.
x_train — набор массивов случайных чисел на отрезке от −100 до +400 (random.uniform поможет) длины size.
y_train — набор массивов «ответов» (результатов перевод из Цельсия в Фаренгейты) для каждого вопроса.
Примените вашу функцию и выведите результат её работы в соответствии с примером ниже:
Напишите функцию mean_squared_error, которая берёт список правильных ответов y_true и список предсказаний y_pred и
по ним вычисляет средний квадрат ошибки.
Если мы обозначим правильные ответы через
[t11,t12,…,t1k],[t21,t22,…,t2k],…,[tn1,tn2,…,tnk], а предсказания — через
[p11,p12,…,p1k],[p21,p22,…,p2k],…,[pn1,pn2,…,pnk],
то функция должна вернуть
MSE=ni=1∑n(ti1−pi1)2+(ti2−pi2)2+…+(tik−pik)2.
В первой стоке дан размер выборки и количество чисел в каждом запросе.
Остальное смотрите из примера.
Поправьте класс Network с констуктором и фукцией для вывода.
На вход даётся число — количество слоёв с учётом входов.
Затем — количество входов/нейронов в этих слоях.
Создайте экземляр сети со случайными параметрами.
В случае использования С++ выводите в виде Network({1, 2, 3}, {1.0, 2.0, 3.0}).
В случае использования rust'а выводите в виде Network::new(vec![1, 2, 3], vec![1.0, 2.0, 3.0]).
В случае хранения коэффициентов не в плоской структуре, выводите не в плоской (coefs=[[1,2,3],[3,4,5]]).
Если используете несколько атрибутов, выводите несколько.
Используете numpy? numpy.array([]) — тоже пойдёт.
Главное — число весов должно быть правильным.
Реализуйте метод predict, принимающий на вход список/кортеж чисел, и вычисляющий на этом входе ответ нейронной сети.
В первой количество слоёв с учётом входов.
Во второй — количество входов/нейронов в этих слоях.
В третьей — параметры сети. Гарантируется, что их ровно столько, сколько нужно (l1+1)l2+(l2+1)l+…+(ln−1+1)ln.
В четвёртой — данные на вход. Гарантируется, что их ровно столько, сколько чисел в нулевом слое.
22212345610010000
2010350406
3323100000101000057010179572020
179572020
Для второго теста веса и процесс вычисления на картинке выше. Эта сеть на входе [x1,x2,x3] всегда выдаёт [x1,57,x3].
Реализуйте метод score для оценки сети.
Метод принимает на вход список запросов x_test, список правильных ответов y_true.
Для каждого запроса необходимо «предсказать» ответ.
После чего вернуть средний квадрат ошибки.
В первой количество слоёв с учётом входов.
Во второй — количество входов/нейронов в этих слоях.
В третьей — параметры сети. Гарантируется, что их ровно столько, сколько нужно (l1+1)l2+(l2+1)l+…+(ln−1+1)ln.
Во четвёртой — число запросов.
Затем строка x_test и сами запросы.
Затем строка y_true и сами ответы.
Реализуйте метод mutate, который создаёт новую сеть из исходной при помощи мутации.
У метода должно быть два параметра: p — вероятность мутации, mx — максимальная величина мутации.
Метод должен создать новую нейронную сеть, каждый коэффициент которой с вероятностью p изменён на случайное число от −mx до mx.
В первой количество слоёв с учётом входов.
Во второй — количество входов/нейронов в этих слоях.
В третьей — параметры сети. Гарантируется, что их ровно столько, сколько нужно (l1+1)l2+(l2+1)l+…+(ln−1+1)ln.
В четвёртой — три числа: вероятность 0≤p≤1, максимальное изменение −1000≤mx≤1000 и необходимое число клонов.
В целом язык python достаточно быстрый.
Но когда дело доходит до того, чтобы «перемолоть» много миллиардов небольших чисел, то оказывается, что не достаточно.
В таких случаях реализация на C++ оказывается в 50-200 раз быстрее :(
Python — это язык.
Эталонной реализацией Python является интерпретатор CPython, поддерживающий большинство активно используемых платформ.
Однако есть и другие реализации.
Одна из них — PyPy.
В ней питоновский код транслируются в Си и компилируется.
За счёт этого теряется часть возможностей CPython, зато числомололки начинают работать в 10-20 раз быстрее.
Текущий листок — как раз числомололки.
Чтобы нейронные сети тренировались быстрее, очень рекомендуется для этого листка использовать PyPy.
Со страницы http://pypy.org/download.html скачайте интерпретатор из раздела в духе «Python 3.6 compatible PyPy3.6
v7.3.0» для вашей операционной системы.
Скачанный архив нужно куда-нибудь разархивировать.
После чего настроить PyCharm на использование этого интерпретатора.
Для этого вы идёте в File->Settings...->Project КакНазвали->Project Interpreter.
Там справа от выбранного «Project Interpreter» есть шестерёнка, после нажатия на которую нужно выбрать «Add...»
В новом окошке слева выбираете «System Interpreter», потом справа — многоточие для выбора пути внучную.
Теперь нужно найти папку, в которую вы разархивировали PyPy, и выбрать в ней файл pypy3.exe.
После этого вы сможете выбрать PyPy как интерпретатор для вашего проекта.
Если всё пошло по плану, то, во-первых, долгое обучение должно стать раз в 10-20 быстрее.
А во-вторых первая строка вывода консоли будет содержать pypy3.6-v7.1.1-win32\pypy3.exe — ваш интерпретатор.
Реализуйте функцию run_evolution, которая будет управлять эволюцией.
Параметры функции:
population — начальная популяция;
epochs — количество смен эпох, которые нужно провести;
x_train и y_train — данные для обучения;
p и mx — параметры для мутаций;
На вход в первой строчке даётся число n — количество поколений, которые нужно провести.
Во второй строчке два числа — параметры мутаций: вероятность 0≤p≤1, максимальное изменение −1000≤mx≤1000.
Создайте популяцию из 50 случайных сетей со структурой [2,3,2], тестовые данные из 10 запросов, в каждом по 2 температуры (см. задачу B1
, gen_dataset) и выполните n поколений отбора.
В каждом поколении выведите лучшую из сетей и её MSE (средний квадрат ошибки) на следующей строчке.
В этой задаче мы будем тренировать сеть со слоями [3, 1] выполнять линейную регрессию.
У нас 3 входа, обозначим из через x,y,z.
Будем искать такое выражение ax+by+cz+d, которое «лучше всего» описывает данные.
На вход даются два числа n и k: число запросов для обучения и число запросов для тестирования.
Затем идёт строка x_train, после которой n строк по 3 числа в каждом.
Затем идёт строка y_train, после которой n строк по 1 числу в каждой (ответы).
Затем идёт строка x_test, после которой k строк по 3 числа в каждом.
Обучите нейронную сеть в течение 2 секунды и предскажите ответы для каждого из тестов.
Если сеть не проходит тесты, то придумывайте, как за две секунды достить лучшего результата обучения.
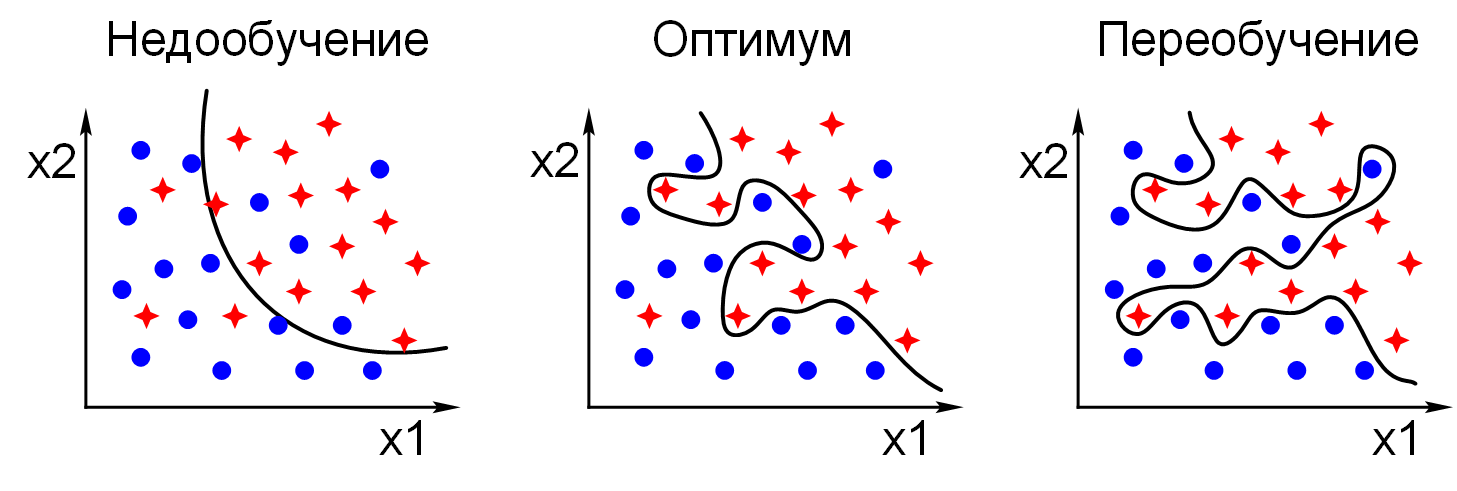
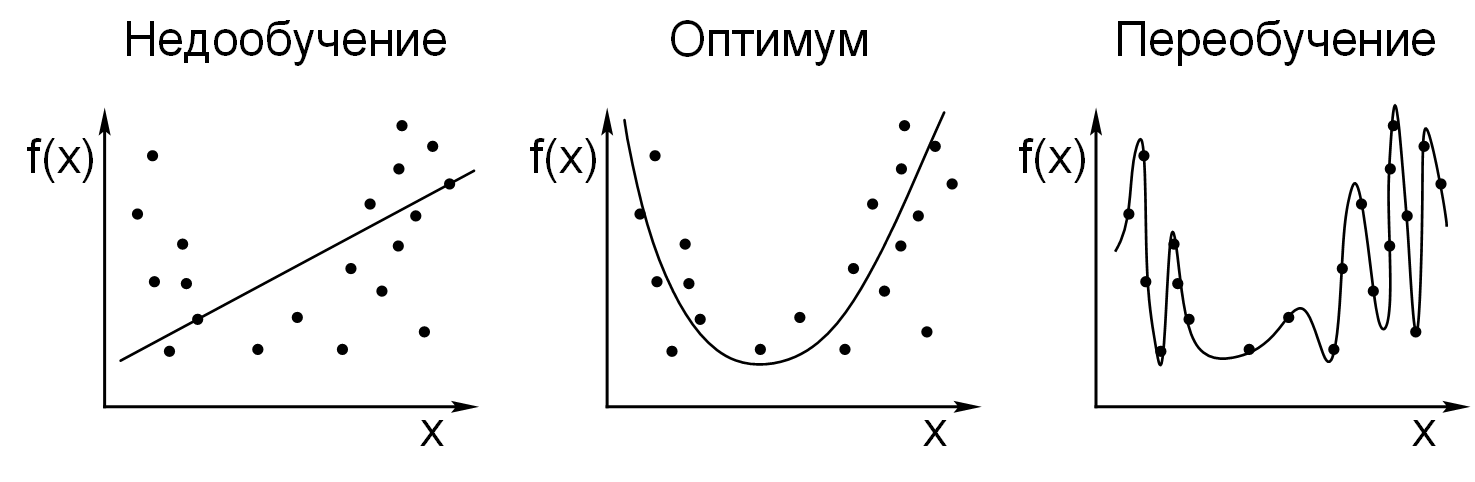
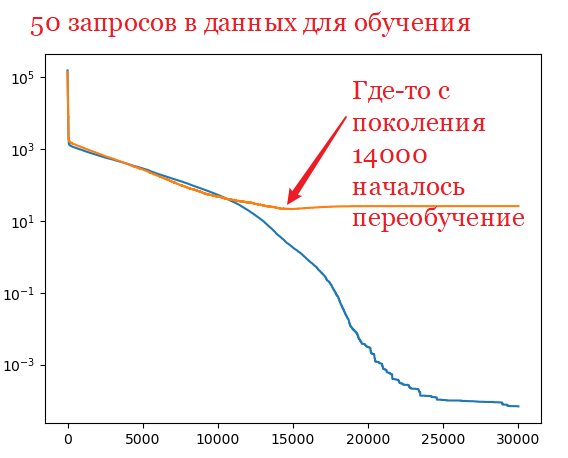
Переобучение (overfitting) – явление, при котором ошибка модели на объектах,
не участвовавших в обучении, оказывается существенно выше, чем ошибка на объектах,
участвовавших в обучении. Переобучение возникает при использовании слишком сложных моделей,
как правило, с большим количеством нейронов и синапсов, либо при слишком долгом процессе
обучения, либо при неудачной обучающей выборке.
Недообучение (underfitting) – явление, при котором ошибка обученной модели оказывается
слишком большой. Недообучение возникает при использовании слишком простых моделей, как правило,
с малым количеством нейронов и синапсов, либо при прекращении процесса обучения до достижения
состояния с достаточно малой ошибкой, либо при неудачной обучающей выборке.
Причины переобучения разнообразные:
слишком мало данных для обучения, либо слишком много нейронов и синапсов в ИНС – модель
запомнила все варианты из обучающей выборки и, таким образом, утратила возможность
обобщения, выдавая запомненные варианты вместо предсказаний;
слишком долгое обучение – модель находит закономерности в шуме (галлюцинирует);
плохо подготовленные данные в обучающей выборке могут привести к тому, что модель будет
давать большую ошибку на новых данных, которые не участвовали в обучении.
Если модель запомнила все варианты в обучающей выборке, то новые примеры она может не угадать
просто потому, что они отличаются от тех, что были в выборке. Эта проблема возникает,
когда обучающая выборка слишком маленькая либо модель ИНС слишком сложная.
Если модель находит закономерности в шуме, то новые данные будут обладать другим шумом,
который всегда есть в данных, тогда ответ модели будет ошибочным. Эта проблема возникает,
когда обучение было слишком долгим и модель просто подогнана под шум в обучающей выборке
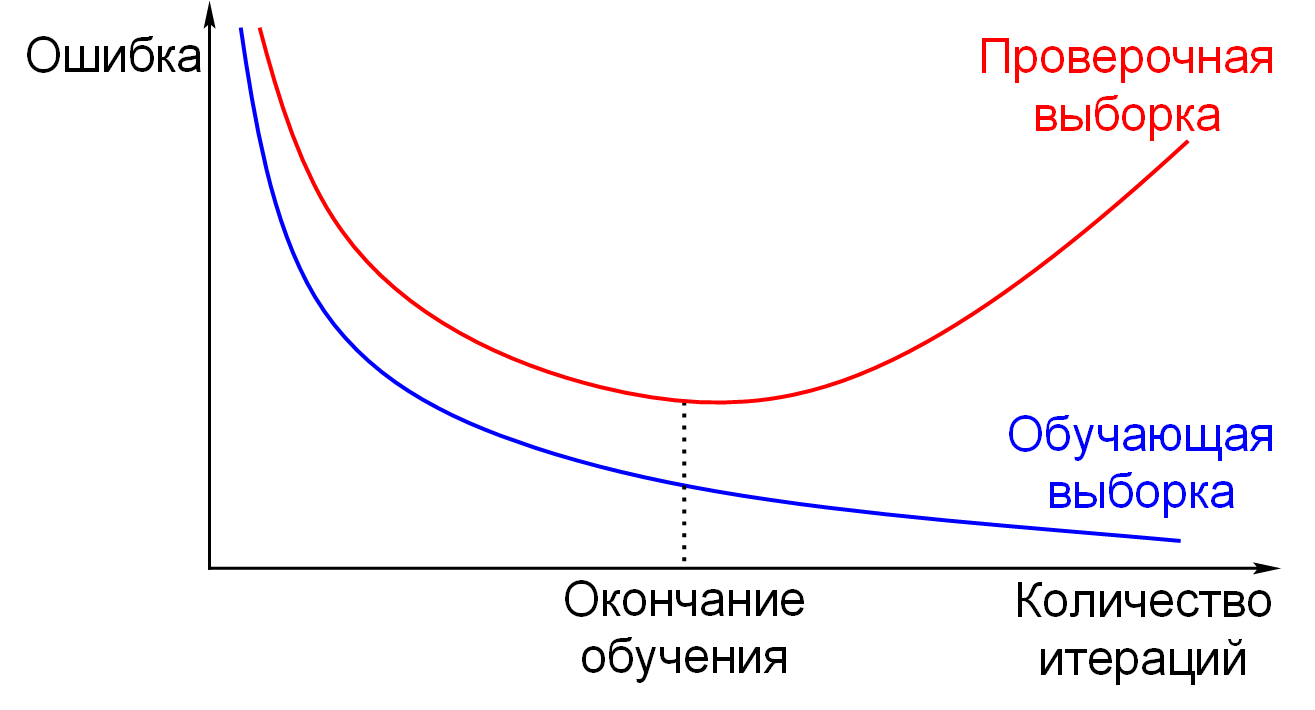
Для того, чтобы контролировать модель на переобучение,
нужно использовать отдельные наборы данных для обучения и оценки.
Данные, на которых происходит оценка качества, не должны участвовать в обучении.
Поэтому имеющиеся данные всегда делят на две части: x_train и x_test (с ответами y_train и y_test).
Для обучения используют только x_train.
Для оценки качества получившейся модели используют только x_test.
Несложно доказать, что если нейрон просто суммирует входы, то ничего хитрее линейной зависимости никакая нейронная сеть выдать не сможет.
Кроме того, у реальных нейронов есть особенность: если сигнал слабый, то нейрон его игнорирует.
Для того, чтобы избавиться от линейности выхода в моделях используется функция активации.
Нейрон выдаёт не просто сумму, а результат применения функции к этой сумме.
В реальности используется много разных функций активации, но мы будем использовать только линейный выпрямитель — ReLU, Rectified linear unit.
ReLU(x)=max(x,0)={0,x,еслиx<0еслиx≥0
Можно доказать (универсальная теорема аппроксимации), что нейронная сеть с одным скрытым слоем и функцией активации ReLU может с любой точность приблизить
любое непрерывное отображение (многомерную функцию) из фиксированного ограниченного множества в фиксированное ограниченное множество.
Например, непрерывные функции от 10 переменных −1000≤xi≤1000 с 5 значениями −10000≤yj≤10000.
Только потребуется очень много нейронов :)
Эту теорему (с некоторым оговорками) вы и сами можете доказать для случая, когда у сети один выходной нейрон.
Нужно начать с того, чтобы получить произвольную букву П с немного покатыми краями.
Итак, без тестовых данных никто не обучает.
Поэтому будем делать тестовые данные.
Чтобы было проще сравнивать успехи разных сетей, в качестве тестовых данных всегда будем использовать арифметическую прогрессию от -100 до 400.
Напишите функцию gen_dataset с тремя параметрами: размер обучающей выборки n, размер тестовой выборки k и количество температур в одном
запросе t.
Функция должна возвращать четыре массива, которые традиционно называются x_train, y_train и x_test и y_test.
x_train — набор массивов случайных чисел на отрезке от −100 до +400 длины n (по t чисел в каждом).
y_train — набор массивов «ответов» (результатов перевод из Цельсия в Фаренгейты) для каждого вопроса.
x_test — набор массивов t одинаковых чисел, представляющих из себя арифметическую прогрессию от −100 до +400 длины k.
y_test — набор массивов «ответов» (результатов перевод из Цельсия в Фаренгейты) для каждого вопроса.
Примените вашу функцию и выведите результат её работы в соответствии с примером ниже (квадратные скобки и запятые выводить по желанию):
Поправьте функцию run_evolution (см. H2): добавьте параметры x_test и y_test — данные для
тестирования.
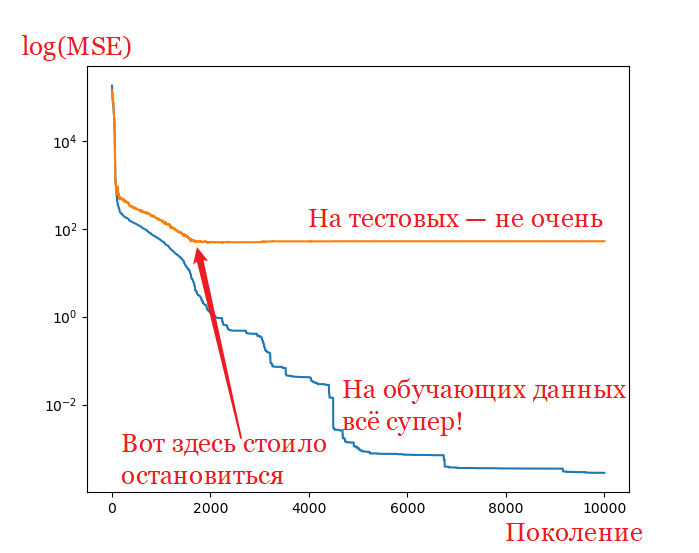
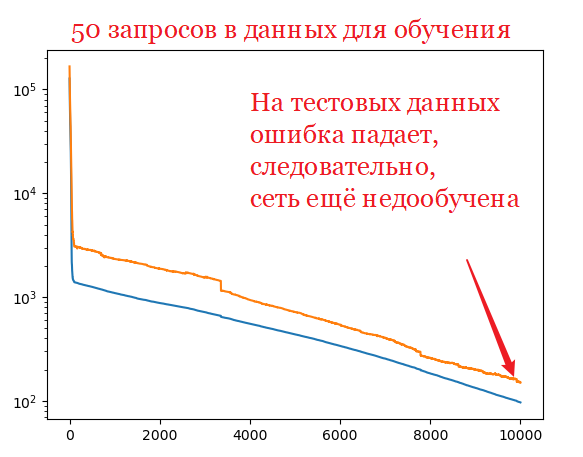
Обучайте сеть со структурой [2, 3, 2] на выборке с 20 строчками, тестируйте на выборке со 100 строчками (везде по 2 числа).
Для каждой популяции кроме ошибки на обучающих данных выведите ошибку на тестовых данных.
Из универсальной теоремы аппроксимации следуюет, что любую непрерывную функцию на квадрате f:[0,100]×[0,100]→[0,1000]
можно приблизить так, чтобы ошибка в любой точке квадрата не превышала 0.1.
И хотя теоретически такая точность достижима, вряд ли у вас она получится :)
В файле I3.txt находится обучающая выборка из 3000 строчек, полученная на основе одной уже известной вам физической функции.
Вам нужно у себя обучить сеть, которая предсказывает её значения на квадрате f:[0,90]×[0,90], и добавить её в программу.
При помощи обученной сети предскажите ответы на тестовых данных.
Для прохождения тестов необходимо, чтобы MSE не превосходила 200.
2 x_test 0.00.010.010.0
0.03.488
Нарисовать график вашей аппроксимации
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
from matplotlib import cm
import numpy as np
classNetwork:
...
ai = Network(...)
fig = plt.figure()
ax = fig.gca(projection='3d')
X = np.linspace(0, 90, 91)
Y = np.linspace(0, 90, 91)
X2d, Y2d = np.meshgrid(X, Y)
Z = np.zeros_like(X2d)
for i inrange(0, 91):
for j inrange(0, 91):
Z[i, j] = ai.predict([i, j])[0]
surf = ax.plot_surface(X2d, Y2d, Z, cmap=cm.coolwarm)
fig.colorbar(surf, shrink=0.5, aspect=5)
plt.show()
В этой части листка мы напишем эмулятор для игры в змейку и обучим нейронную сеть, которая будет в неё играть.
Здесь у нас нет данных для обучения, зато есть среда, с которой можно взаимодействовать.
Будем запускать игры и смотреть, какая из сетей лучше играет.
Численную характеристику вот этого «лучше играет» будем использовать для отбора сетей.
Чтобы всё это реализовать, понадобятся:
Класс SnakeGame, который будет хранить текущее состояние поля и взаимодействовать с сетью. В частности:
SnakeGame.__init__ — конструктор. Берёт размер поля и сохраняет внутри себя; Инициирует случайное положение змейки и яблока;
SnakeGame.__str__ — вывод, чтобы можно было контролировать ситуацию;
SnakeGame.gen_features — вычисление входа для нейронной сети на основе текущей позиции;
SnakeGame.make_move — сделать ход в соответствии с ответом нейронной сети и посчитать очки за ход;
SnakeGame.play — полностью проиграть одну партию;
run_evolution — новая версия эволюции для змейки;
Обучение сети будет проиходить точно также, как и раньше.
Только для вычисления очков потребует провести несколько игр с данной змейкой.
Реализуйте конструктор для эмулятора змейки.
Он должен принимать на вход ширину и высоту поля.
И необязательные параметры — список координат каждой клетки змейки в порядке от хвоста к голове и координаты яблока.
Для хранения координат будем использовать одно число — порядковый номер ячейки, если считать слева направо и сверху вниз.
То есть число y⋅W+x, где (x,y) — двумерные координаты, а W — ширина поля.
Конструктор должен подготовить всё для запуска и проведения игры.
Для этого нужно выбрать случайное положение для змейки длины 2, и другое случайное положение для яблока.
Также нужно подготовить структуры для эффективного хранения змейки.
Как хранить эффективно хранить змейку
Лучше сначала придумайте что-нибудь своё...
Будем хранить координаты клеток змейки одновременно в деке (см. класс
deque из модуля collections) и в множестве.
В дек в голову мы будем добавлять новое положение головы и удалять клетку хвоста.
А множество нужно для быстрой проверки самопересечения змейки.
Метод __str__ должен вывести поле в удобном для просмотра формате. См. пример.
Реализуйте метод gen_features, который на основе текущей позиции создаст список фич для передачи нейронной сети.
В качестве фич будем использовать 4 числа:
Правда ли, что спереди свободно (1 — свободно, 0 — занято);
Правда ли, что слева свободно;
Правда ли, что справа свободно;
Угол на яблоко (от −π до π);
105612121314448
0112.356194490192345
Число 2.356194490192345 — это 135∘=135/180⋅π, так как голова смотрит наверх, а для поворота на яблоко нужно повернуть на 135∘ в
положительном направлении.
Реализуйте метод make_move, который на основе ответа нейронной сети сделает ход и вернёт число — оценку «качества хода».
Метод принимает массив из трёх чисел: то, насколько сеть хочет повернуть налево, насколько хочет двигаться прямо, и насколько хочет повернуть направо.
Нужно выбрать среди этих чисел максимальное, после чего сделать ход.
Также нужно оценить «качество» хода.
Давайте договоримся, что поражение — это −100 очков.
Остальное попробуйте придумать сами.
Если змейка съела яблоко, то нужно выбрать новое незанятое случайное положение для яблока.
Подсказка
Если уже попробовали, а оно не учится...
Например, если голова змейки приблизилась к яблоку, то можно дать 2 очка. А если отдалилась — то -3 очка.
Это для того, чтобы движение по циклу не было выгодным.
Также если змейка сделала больше ходов без съедения яблока, чем удвоенный периметр, то нужно признать её техничесчкое поражение.
Реализуйте метод play, который принимает на вход нейронную сеть, проводит один раунд игры и возвращает суммарные очки за этот раунд.
В качестве теста даются размеры поля и параметры нейронной сети с 4 входами и 3 выходами.
Если змейка сделала больше ходов без съедения яблока, чем удвоенный периметр, то нужно признать её техничесчкое поражение и закончить игру.