Рекурсивная генерация комбинаторных объектов довольна удобна и часто позволяет быстро решить задачу. Однако у этого подхода есть несколько недостатков. При использовании рекурсивных генераторов при большой глубине рекурсии довольно сильно просаживается производительность. Эту проблему можно частично обойти, если не использовать генераторы, а использовать рекурсивную функцию, одним из параметров которой является префикс или суффикс собираемой последовательности. Это позволяет ускорить код в несколько раз, но результат несколько менее нагляден. Другая фундаментальная проблема заключается в том, что рекурсивно мы можем перебрать только все объекты в определённом порядке. По данной последовательности нет никакого «дешёвого» способа найти предыдущую или следующую, либо перескочить в процессе работы к некоторой определённой последовательности. Такая необходимость может возникнуть при оптимизации больших переборов: иногда становится понятно, что целую ветку последовательностей можно откинуть.
Поэтому в этом листке будет реализован другой подход к перебору комбинаторных объектов. Решение каждой задачи будет состоять из двух частей:
- Построение первого в заданном порядке объекта;
- Для любого данного объекта построение следующего за ним объекта.
Для нахождения следующего объекта обычно нужно научиться находить самых правый или самый левый элемент текущей последовательности, который можно уменьшить или увеличить. Например, если мы перебираем все двоичные последовательности в лексикографическом порядке, то для того, чтобы получить следующую последовательность, нужно найти самый правый ноль, заменить его на единицу, а все единицы справа от него заменить на нули. Если ни одного нуля нет, то перебор окончен.
Все задачи на перебор комбинаторных объектов должны решаться при помощи нерекурсивного генератора (или нерекурсивной функции в C++). Во всех задачах, предполагающих этот перебор использовать, можно пользоваться рекурсивными решениями из предыдущего листка.
Замечание по вводу-выводу
Следует иметь в виду, что во всех высокоуровневых языках программирования для большинства простых вещей есть пяток разных решений, производительность которых может отличаться на несколько порядков. Одной из таких вещей является вывод списков в Python. Вот самый простой и наивный способ выводить последовательности списков чисел:for row in some_iterator:
for i in range(len(row)):
print(row[i], end=" ")
print()
Вот другой способ, о котором мы недавно узнали (кто ещё помнит, почему это работает?):
for row in some_iterator:
print(*row)
Эти способы могут быть в тысячи раз медленнее (при большом объёме данных), чем такой способ:
for row in some_iterator:
print(' '.join(map(str, row)))
Поэтому если вы пишите вывод на олимпиаде, то первые два варианта лучше не использовать.
При некоторой ловкости можно сделать вывод такого сорта в одну строчку, используя '\n'.join, map, lambda, немного магии и функционального программирования.
Кто сумеет придумать, как?
Упражнения
01: Двоичные последовательности
По данному натуральному n≤15 выведите все двоичные последовательности длины n в лексикографическом порядке.
| Ввод | Вывод |
|---|---|
3 |
0 0 0 |
02: Потратить все деньги
Однажды Вовочке на день рожденья подарили S рублей.
Он без ума от булочек, поэтому немедленно отправился в кондитерскую.
Там продаются K разных булочек, для каждой известна её цена.
Вовочка хочет потратить все деньги и не так уж важно, на какие именно булочки.
Сможет ли он это сделать?
В первой строчке даны натуральные числа S, количество денег у Вовочки,
и K — количество булочек в кондитерской.
В следующей строчки перечислены стоимости каждой булочки.
Если Вовочка может потратить все деньги, то выведите через пробел номера булочек, которые он при этом купит (выведите любой способ).
Если же это ему никак не удастся, то выведите слово Impossible.
| Ввод | Вывод |
|---|---|
100 10 |
0 9 |
101 10 |
Impossible |
03: Двоичные последовательности в обратном порядке
По данному натуральному n≤15 выведите все двоичные последовательности длины n в обратном лексикографическом порядке.
| Ввод | Вывод |
|---|---|
3 |
1 1 1 |
04: Двоичные последовательности без двух единиц подряд в обратном лексикографическом порядке
По данному натуральному n≤20 выведите все двоичные последовательности длины n, не содержащие двух единиц подряд, в обратном лексикографическом порядке.
| Ввод | Вывод |
|---|---|
3 |
1 0 1 |
Ясно, что самая первая последовательность имеет вид [1, 0, 1, 0, ...].
Теперь для того, чтобы найти следующую последовательность, нужно найти самую правую единицу.
Начиная с неё хвост последовательности имеет вид [1, 0, 0, 0, ...],
его нужно заменить на [0, 1, 0, 1, ...].
Последней последовательностью будет [0, 0, 0, 0, ...].
Для того, чтобы упростить поиск момента, когда пора остановиться, можно добавить в начало последовательности «бонусные» [1, 0].
Тогда нужно yield'ить последовательности (вернее срезы [2:]) только пока нулевой элемент последовательности равен 1.
05: Вовочка берётся за ум
После того, как Вовочка потратил все деньги на булочки, ему стало грустно.
Он решил, что станет супер-ботаном и у него больше никогда не будет проблем с булочками.
Для реализации этого плана он зарегистрировался на курсере,
чтобы проходить он-лайн курсы.
Однако курсы достаточно сложные, и Вовочка пока не способен слушать лекции два дня подряд.
Для каждого из K дней Вовочка для себя определил ценность лекции в этот день.
Помогите ему выбрать лекции с максимальной ценностью.
В первой строчке дано натуральное число K — количество дней.
Во второй строчке даны K целых чисел — ценности лекций для Вовочки (некоторые лекции он считает вредными).
Выведите в порядке возрастания номера дней, в которые лучше всего слушать лекции Вовочке.
| Ввод | Вывод |
|---|---|
3 |
0 2 |
5 |
2 |
06: Двоичные последовательности длины n содержащие k единиц
По данным натуральным n и k (0≤k≤n, n≥1) выведите все двоичные последовательности длины n, содержащие ровно k единиц в лексикографическом порядке.
| Ввод | Вывод |
|---|---|
4 2 |
0 0 1 1 |
Ясно, что самая первая последовательность — [0, ..., 0, 1, ..., 1].
В каком случае s-й член последовательности можно увеличить, не меняя предыдущие?
Когда после s-го члена есть 1, которую для баланса мы заменим на 0.
То есть нужно найти самый правый 0, за которым стоят единицы.
В этом случае хвост последовательности имеет вид [0, 1, ..., 1, 0, ..., 0] (пусть там i единиц, i>0).
Если мы заменим s-й член на 1, то оставшийся хвост нужно заменить на лексикографически минимальную последовательность, в которой i-1 единица,
то есть [0, 1, ..., 1, 0, ..., 0] заменяется на [1, 0, ..., 0, 1, ..., 1].
Как обычно, для того, чтобы упростить отлов момента, когда пора остановиться, добавим слева «виртуальный» [0].
Тогда нужно yield'ить последовательности (вернее срезы [1:]) только пока нулевой элемент последовательности равен 0.
07: Вовочка и поднабор с нулевой суммой
На курсе по алгоритмам Вовочке предлагалось решить следующую NP-полную задачу:
Даны N чисел. Можно ли среди них выбрать K так, чтобы их сумма равнялась нулю?
Решите её и вы.
В первой строчке даны натуральные числа N K.
Во второй строчке даны N целых чисел.
Выведите через пробел в порядке возрастания K номеров чисел, имеющих сумму 0.
Если такого набора нет, то выведите слово Impossible.
| Ввод | Вывод |
|---|---|
3 2 |
1 2 |
3 2 |
Impossible |
08: Возрастающие последовательности в обратном порядке
По данным натуральным n и k (n≤k) выведите все возрастающие последовательности длины n, состоящие из чисел 1..k в обратном лексикографическом порядке.
| Ввод | Вывод |
|---|---|
3 5 |
3 4 5 |
Как и раньше, начальная последовательность очевидна: это [k-n+1, ..., k-1, k].
В каком случае можно уменьшить на единицу s-ый элемент?
Когда он хотя бы на 2 больше предыдущего, либо он начальный.
Для обратного порядка нужно найти самый правый такой s.
Пусть мы уменьшили s-ый элемент на единицу, что нужно написать в хвост?
Лексикографически максимальную последовательность, то есть [k-n+p, ..., k-1, k].
Как и выше, для того, чтобы упростить критерий останова, добавим слева «фальшивые» [-2, 0].
Тогда нужно yield'ить последовательности (вернее срезы [2:]) только пока первый элемент последовательности равен 0.
09: Перестановки
Дано натуральное число n. Выведите всевозможные перестановки чисел от 1 до n в лексикографическом порядке.
| Ввод | Вывод |
|---|---|
3 |
1 2 3 |
Первой будет перестановка [1, 2, ..., n], последней — [n, n-1, ..., 1].
В каком случае s-ый член перестановки можно увеличить, не меняя предыдущих?
Ответ: если он меньше какого-либо из последующих членов.
Мы должны найти самый правый такой s, если X — наша текущая последовательность, то
x[s] < x[s+1] > x[s+2] > ... > x[n-1].
Значение x[s] нужно увеличить минимальным образом, то есть найти среди x[s+1]..x[n-1] наименьшее число,
большее его.
Поменяв x[s] с ним местами, останется расположить числа с номерам s+1..n-1 так,
чтобы перестановка была наименьшей, то есть в возрастающем порядке.
Это всё весьма облегчается тем, что элементы s+1..n-1 уже идут в убывающем порядке,
поэтому хвост нужно склеить из правой части хвоста (той части, где элементы меньше x[s]) в обратном порядке, x[s], и левой части хвоста (той части, где элементы больше x[s]) тоже в обратном порядке.
Примерчик: пусть хвост начиная с x[s] такой: [5, 9, 8, 7, 3, 2, 1].
Минимальный элемент, больший 5 — это 7.
Поэтому новый хвост будет [7] + [3, 2, 1][::-1] + [5] + [9, 8][::-1], то есть [7, 1, 2, 3, 5, 8, 9].
И снова для того, чтобы упростить поиск момента для остановки, добавим слева «искусственный» [0].
Тогда нужно yield'ить последовательности (вернее срезы [1:]) только пока нулевой элемент последовательности равен 0.
10: Вовочка и задача коммивояжёра
Следующим шагом для продолжения обучения Вовочка решил выбрать для себя лучший университет.
Он собрал список из N + 1 лучшего университета (университет в городе Вовочки имеет номер 0).
На страничке awesome-python он нашёл ссылку на пакет robobrowser, при помощи которого с известного сайта добыл стоимости перелётов из города с i-м университетом в город с j-м университетом для всех i и j.
Вовочка хочет найти самый дешёвый круговой маршрут для посещения всех ВУЗов.
В первой строчки дано число N --- число университетов, не считая университета в родном городе Вовочке.
В следующих N + 1 строках дана таблица с ценами перелётов из города с i-м университетом в город с j-м.
Выведите в первой строчке минимальную стоимость перелётов,
а во второй — любую из последовательностей перелётов с минимальной стоимостью.
| Ввод | Вывод |
|---|---|
3 |
16000 |
11: Расстановки ферзей
Известно, что на шахматной доске размером 8×8 можно расставить 8 ферзей не бьющих друг друга, причем сделать это можно 92 способами.
Дано натуральное n≤8. Определите сколькими способами на доске n×n можно расставить n мирных ферзей.
| Ввод | Вывод |
|---|---|
8 |
92 |
12: Разбиение на невозрастающие слагаемые в обратном порядке
Дано натуральное число n. Выведите всевозможные его разбиения на слагаемые, упорядоченные в порядке невозрастания. Сами разбиения необходимо выводить в обратном лексикографическом порядке.
| Ввод | Вывод |
|---|---|
5 |
5 |
Итак, нужно последовательно перебрать все разбиения начиная с [n], заканчивая [1, 1, ..., 1].
Каждым шагом уменьшать нужно первый справа член, не равный 1; найдя его, уменьшим на 1, а следующие возьмём максимально возможными: равными ему, пока хватает суммы, а последний — сколько останется.
Здесь для того, чтобы упростить поиск момента для остановки, добавим слева «флаг» [2].
Тогда нужно yield'ить последовательности (вернее срезы [1:]) только пока нулевой элемент последовательности равен 2.
13: Всё по i
Во время тура по университетам Вовочка обнаружил замечательную кондитерскую: «Всё по i».
В ней для всех i от 1 до 30 были булочки за i долларов.
Былая любовь к булочкам проснулась в нём, и он решил купить булочек на все оставшиеся S долларов.
В первой строчке дано натуральное число S — доступная Вовочке сумма денег.
В следующей строчке даны min(S, 30) натуральных чисел — привлекательность булочек каждой стоимости для Вовочки.
Выведите любой из лучших наборов булочек, которые можно купить за S долларов.
| Ввод | Вывод |
|---|---|
10 |
7 1 1 1 |
14: Следующее слово
Для данного слова (последовательности строчных латинских букв) выведите следующее за ним (в лексикографическом порядке) слово, которое может быть получено из данного перестановкой букв (анаграмму). Если данное слово уже является последним среди всех своих анаграмм, то необходимо вывести первую возможную (в лексикографическом порядке) анаграмму. Программа получает на вход последовательность слов и должна вывести для каждого полученного на вход слова результат.
| Ввод | Вывод |
|---|---|
aab |
aba |
15: Правильные скобочные последовательности
Дано натуральное числo n. Выведите все правильные скобочные последовательности, состоящие из n открывающихся круглых скобок и n закрывающихся скобок в лексикографическом порядке.
| Ввод | Вывод |
|---|---|
3 |
((())) |
Начинается всё, конечно, с последовательности (((..()..))).
В целом алгоритм выглядит следующим образом: найдем такую самую правую открывающую скобку, которую мы имеем право заменить на закрывающую (так, чтобы в этом месте правильность не нарушалась), а всю оставшуюся справа строку заменим на лексикографически минимальную: т.е. сколько-то открывающих скобок, затем все оставшиеся закрывающие скобки. Иными словами, мы пытаемся оставить без изменения как можно более длинный префикс исходной последовательности, а в суффиксе эту последовательность заменяем на лексикографически минимальную.
Осталось научиться искать эту самую позицию первого изменения. Для этого будем идти по строке справа налево и подсчитывать баланс depth открытых и закрытых скобок (при встрече открывающей скобки будем уменьшать depth, а при закрывающей — увеличивать). Если в какой-то момент мы стоим на открывающей скобке, а баланс после обработки этого символа больше нуля, то мы нашли самую правую позицию, от которой мы можем начать изменять последовательность (в самом деле, depth > 0 означает, что слева имеется не закрытая ещё скобка). Поставим в текущую позицию закрывающую скобку, затем максимально возможное количество открывающих скобок, а затем все оставшиеся закрывающие скобки, — ответ найден.
Если мы просмотрели всю строку и так и не нашли подходящую позицию, то текущая последовательность — последняя, и пора заземляться.
Коды Грея
Иногда бывает полезно перечислять объекты в таком порядке, чтобы каждый следующий минимально отличался от предыдущего. Например, это позволило бы во второй задаче при переходе к очередной последовательности не вычислять заново полную сумму, а получить её всего лишь одним арифметическим действием из предыдущей суммы. Это позволило бы ускорить перебор в разы.
В 4А томе книги The Art of Computer Programming известного американского математика и специалиста в области компьютерных наук Дональда Кнута, целиком посвящённой комбинаторным алгоритмам (вдумайтесь, 900 страниц, посвящённых теме этого листочка!), кодам Грея посвящено несколько десятков страниц.
Изначально код Грея предназначался для защиты от ложного срабатывания электромеханических переключателей. Сегодня коды Грея широко используются для упрощения выявления и исправления ошибок в системах связи, а также в формировании сигналов обратной связи в системах управления.
Пусть есть вращающаяся ось, и мы хотим поставить датчик угла поворота этой оси.
Насадим на ось барабан и сделаем на нём несколько дорожек из белых и чёрных частей, а также установим по фотоэлементу на каждую дорожку:
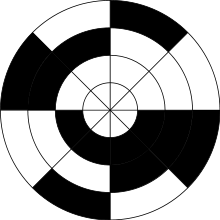 По сигналам с фотоэлементов мы сможем понять, в какой половине, четвертушке, восьмушке и т.д. расположен угол поворота барабана.
Эта идея имеет, однако, недостаток: в момент пересечения границ сразу нескольких фотоэлементов могут менять сигнал, и если эти изменения произойдут не совсем одновременно (а они так и произойдут, не сомневайтесь!), то на какое-то время показания фотоэлементов будут бессмысленными.
Коды Грея позволяют избежать этой опасности.
Сделаем так, чтобы на каждом шаге менялось показание лишь одного фотоэлемента:
По сигналам с фотоэлементов мы сможем понять, в какой половине, четвертушке, восьмушке и т.д. расположен угол поворота барабана.
Эта идея имеет, однако, недостаток: в момент пересечения границ сразу нескольких фотоэлементов могут менять сигнал, и если эти изменения произойдут не совсем одновременно (а они так и произойдут, не сомневайтесь!), то на какое-то время показания фотоэлементов будут бессмысленными.
Коды Грея позволяют избежать этой опасности.
Сделаем так, чтобы на каждом шаге менялось показание лишь одного фотоэлемента:
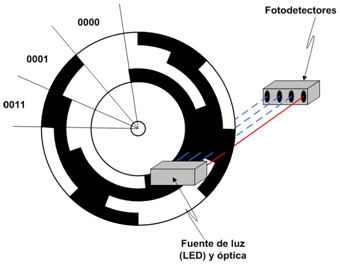


16: Бинарный код Грея при помощи рекурсии
Бинарный код Грея можно определить многими эквивалентными способами.
Например, если Γn обозначает бинарную последовательность Грея, состоящую из
списков длины n, то можно определить Γn рекурсивно, с помощью следующих двух
правил:
Γ0 пусто, Γn+1 = 0Γn, 1ΓRn.
Здесь ΓRn — обозначает последовательность Γn в обратном порядке.
Поскольку последняя строка в Γn эквивалентна
первой строке в ΓRn, ясно, что на каждом шаге Γn+1 изменяется ровно один
бит, если Γn обладает тем же свойством.
Дано число n. Выведите бинарный код Грея длины n при помощи рекурсивного генератора.
| Ввод | Вывод |
|---|---|
4 |
0 0 0 0 |
Добавьте необязательный параметр в генератор — направление кода. По умолчанию направление обычное. Если же направление перевёрнутое, то нужно выдавать 1Γn−1, 0ΓRn−1
17: Бинарный код Грея при помощи битовых операций
Оказывается, бинарный код Грея можно получить буквально за 4 строчки кода при помощи цикла, функции bin и трёх битовых операций.
Получится что-то в этом духе:
def gray_bin(n):
for i in range(1 << n):
cur = bin(mystical_code)[2:]
cur = '0' * (n - len(cur)) + cur
yield cur
| Ввод | Вывод |
|---|---|
4 |
0000 0001 0011 0010 0110 0111 0101 0100 1100 1101 1111 1110 1010 1011 1001 1000 |
Может быть тогда сразу плюсик поставить? >>:->
18: Бинарный код Грея без внутренних циклов
Коды Грея позволяют существенно ускорить решение задач на подобие задачи 02:
так как при переходе к следующей последовательности меняется ровно одно значение,
то для вычисления новой суммы также требуется ровно одна арифметическая операция.
Для применения в задаче 2 нам не нужна вся последовательность нулей и единиц,
достаточно лишь получать индекс j и знак +1/-1:
тогда к текущей сумме нужно будет прибавить j-й элемент массива, умноженный на знак.
Для эффективного перебора последовательностей Гидеоном Эрлихом (Gideon Ehrlich) в 1973 году предложен следующий поразительно эффективный алгоритм: он выполняет только пять операций присваивания и одну проверку завершения алгоритма между соседними выдачами.
Алгоритм Эрлиха:
- [Инициализация.] ai=−1 для i=0,…,n−1, fi=i для i=0,…,n;
- [Проверка завершения.] Если f0≥n, то завершить работу;
- [Выбор j.] Установить j=f0, f0=0, fj=fj+1, fj+1=j+1;
- [Посещение.] Установить aj=−aj и выдать пару j,aj. Вернуться к п.2.
Почему это работает? Это хорошая задача. Рекомендую заинтересованным и олимпиадникам разобраться и сдать устно.
| Ввод | Вывод |
|---|---|
1 |
0 1 |
2 |
0 1 |
3 |
0 1 |
19: Потратить все деньги — 2
Решите задачу 02 при ограничениях n≤20.
| Ввод | Вывод |
|---|---|
100 10 |
0 9 |
101 10 |
Impossible |
20: Перестановки смежными обменами
Коды Грея позволяют эффективно генерировать все последовательности из нулей и единиц длины n. Те же рассуждения применимы и к генерации перестановок. Простейшим возможным изменением перестановки является обмен соседних элементов. При этом возникает естественный вопрос «Можно ли обойти все перестановки, обменивая на каждом шаге местами только два соседних элемента?» Если можно, то программа обхода всех перестановок в целом зачастую будет проще и быстрее, поскольку будет требовать каждый раз вычисления только одного обмена вместо обработки всего нового массива заново (см. задачу 10). Хорошая новость: простой алгоритм позволяет сгенерировать все n! перестановок с помощью n!-1 смежных обменов. Кроме того, еще один смежный обмен возвращает нас в начальное состояние, так что мы получаем гамильтонов цикл, аналогичный бинарному коду Грея.
На вход даётся число n. Напишите генератор, который последовательно выдаёт все n! перестановок так, что соседние перестановки отличаются лишь обменом соседних элементов.
| Ввод | Вывод |
|---|---|
3 |
1 2 3 |
Идея заключается в том, чтобы взять такую последовательность для {1,…,n−1} и вставить число n в каждую из перестановок всеми возможными способами.
Например, если n=4, то последовательность (123,132,312,321,231,213) при
вставке 4 во все четыре возможные позиции приводит к следующим столбцам массива:
1234 1324 3124 3214 2314 2134 1243 1342 3142 3241 2341 2143 1423 1432 3412 3421 2431 2413 4123 4132 4312 4321 4231 4213Теперь мы получаем искомую последовательность, читая первый столбец сверху вниз, второй — снизу вверх, третий — сверху вниз, ..., последний — снизу вверх: (
1234,1243,1423,4123,4132,1432,1342,1324,3124,3142,..., 2143,2134).
Для того, чтобы упростить генерацию этой последовательности, построим биекцию между множеством перестановок
и множеством последовательностей y0,…,yn−1, в которых yi≤i.
А именно каждой перестановки поставим в соответствие последовательность y0,…,yn−1,
где yi — количество чисел, меньших i+1 и стоящих левее i+1 в этой перестановке.
Взаимную однозначность легко доказать по индукции:
перестановка длины n получается из перестановки длины n−1 добавлением числа n, котором можно поставить в любое из n мест.
При этом к сопоставляемой последовательности добавляется ещё один член, принимающий значения от 0 до n−1, а предыдущие члены не меняются.
При этом оказывается, что транспозиции двух соседних чисел в перестановке соответствует изменение на единицу ровно одного из членов сопоставляемой последовательности.
Вот чему соответствуют перестановки, перечисленные выше:
0000 0010 0020 0120 0110 0100 0001 0011 0021 0121 0111 0101 0002 0012 0022 0122 0112 0102 0003 0013 0023 0123 0113 0103Заметим при этом, что увеличение на единицу числа yi ведёт к обмену числа i+1 с левым соседом, а уменьшение — c правым. Будем для каждого i хранить текущую позицию числа i+1 в перестановке в списке
positions, а также будем хранить направление изменения каждого из чисел yi в списке directions.
Изначально positions[i] = i и directions[i] = +1.
Будем идти по списку yi справа налево и пытаться изменить число yi на значение directions[i].
В случае успеха мы делаем обмен числа i+1 с соседом, соответствующим directions[i].
Иначе (если мы упёрлись в 0 или i), то мы меняем знак у directions[i] и делаем шаг налево (уменьшаем i на единицу).
Permutation: 1 2 3.4 inversions: 0 0 0 0 positions: 0 1 2 3 directions: +1 +1 +1 +1 Permutation: 1 2.4 3 inversions: 0 0 0 1 positions: 0 1 3 2 directions: +1 +1 +1 +1 Permutation: 1.4 2 3 inversions: 0 0 0 2 positions: 0 2 3 1 directions: +1 +1 +1 +1 Permutation: 4 1 2.3 inversions: 0 0 0 3 positions: 1 2 3 0 directions: +1 +1 +1 +1 Permutation: 4.1 3 2 inversions: 0 0 1 3 positions: 1 3 2 0 directions: +1 +1 +1 -1 Permutation: 1 4.3 2 inversions: 0 0 1 2 positions: 0 3 2 1 directions: +1 +1 +1 -1 Permutation: 1 3 4.2 inversions: 0 0 1 1 positions: 0 3 1 2 directions: +1 +1 +1 -1 Permutation: 1.3 2 4 inversions: 0 0 1 0 positions: 0 2 1 3 directions: +1 +1 +1 -1 Permutation: 3 1 2.4 inversions: 0 0 2 0 positions: 1 2 0 3 directions: +1 +1 +1 +1 Permutation: 3 1.4 2 inversions: 0 0 2 1 positions: 1 3 0 2 directions: +1 +1 +1 +1 Permutation: 3.4 1 2 inversions: 0 0 2 2 positions: 2 3 0 1 directions: +1 +1 +1 +1 Permutation: 4 3 1.2 inversions: 0 0 2 3 positions: 2 3 1 0 directions: +1 +1 +1 +1 Permutation: 4.3 2 1 inversions: 0 1 2 3 positions: 3 2 1 0 directions: +1 +1 -1 -1 Permutation: 3 4.2 1 inversions: 0 1 2 2 positions: 3 2 0 1 directions: +1 +1 -1 -1 Permutation: 3 2 4.1 inversions: 0 1 2 1 positions: 3 1 0 2 directions: +1 +1 -1 -1 Permutation: 3.2 1 4 inversions: 0 1 2 0 positions: 2 1 0 3 directions: +1 +1 -1 -1 Permutation: 2 3 1.4 inversions: 0 1 1 0 positions: 2 0 1 3 directions: +1 +1 -1 +1 Permutation: 2 3.4 1 inversions: 0 1 1 1 positions: 3 0 1 2 directions: +1 +1 -1 +1 Permutation: 2.4 3 1 inversions: 0 1 1 2 positions: 3 0 2 1 directions: +1 +1 -1 +1 Permutation: 4 2 3.1 inversions: 0 1 1 3 positions: 3 1 2 0 directions: +1 +1 -1 +1 Permutation: 4.2 1 3 inversions: 0 1 0 3 positions: 2 1 3 0 directions: +1 +1 -1 -1 Permutation: 2 4.1 3 inversions: 0 1 0 2 positions: 2 0 3 1 directions: +1 +1 -1 -1 Permutation: 2 1 4.3 inversions: 0 1 0 1 positions: 1 0 3 2 directions: +1 +1 -1 -1 Permutation: 2 1 3 4 inversions: 0 1 0 0 positions: 1 0 2 3 directions: +1 +1 -1 -1
Оптимизации решения «сложных» задач
В этом разделе мы рассмотрим варианты оптимизации решения «сложных» задач — перебор с возвратом и метод ветвей и границ.
Перебор с возвратом
Общая схема рекурсивного перебора с возратом такая:def Перебор(Ситуация):
if Ситуация конечная:
Завершающая обработка
else:
for Действие in Множество всех возможных действий:
Применить Действие к Ситуация
Перебор(Ситуация)
откатить Действие назад
В общем случае, алгоритм перебора с возвратом содержит тест, который по данной подзадаче быстро выдаёт один из трёх ответов:
- неудача: подзадача не имеет решения;
- успех: найдено решение подзадачи;
- неопределённость.
Например в задаче о мирных ферзях неудача — новый ферзь бьёт одного из предыдущих, успех — ферзь успешно поставлен на последнюю линию, неопределённость — новый ферзь не бьёт ни одного из старых.
Более подробный нерекурсивный общий вид алгоритма перебора с возвратами:
начать с некоторой задачи P[0]
S = {P[0]} # {множество активных подзадач}
пока S не пусто:
выбрать подзадачу P ∈ S и удалить её из S
разбить P на меньшие подзадачи P[1], P[2], ... , P[k]
для каждой P[i]:
если тест(P[i]) = успех:
вернуть найденное решение
если тест(P[i]) = неудача:
отбросить P[i]
иначе:
добавить P[i] в S
сообщить, что решения нет
При удачном подборе и реализации процедур тест, выбрать и разбить перебор с возвратами может быть вполне практичным.
Метод ветвей и границ
Этот метод может быть использован не только для задач поиска, но и для задач оптимизации. Допустим, мы решаем задачу минимизации (для задачи максимизации всё аналогично). Как и раньше, мы рассматриваем частичные решения. Нам необходимо понять, какие из них заведомо не приведут к оптимальному решению, чтобы их отбросить и сэкономить время. Отбросить подзадачу можно, если мы знаем, что на этом пути получится решение, худшее уже найденного в другой ветви. Но откуда мы это можем узнать? Для этого надо использовать нижнюю оценку стоимости решения.начать с некоторой задачи P[0]
S = {P[0]} # {множество активных подзадач}
пока S не пусто:
выбрать подзадачу (частичное решение) P ∈ S и удалить её из S
разбить P на меньшие подзадачи P[1], P[2], ... , P[k]
для каждой P[i]:
если P[i] является полным решением:
обновить текущий_минимум с учётом P[i]
иначе если нижняя_оценка(P[i]) < текущий_минимум:
добавить P[i] в S
вернуть текущий_минимум
Упражнения
21: Расстановки ферзей
Известно, что на шахматной доске размером 8×8 можно расставить 8 ферзей не бьющих друг друга, причем сделать это можно 92 способами.
Дано натуральное n≤12. Определите сколькими способами на доске n×n можно расставить n мирных ферзей.
| Ввод | Вывод |
|---|---|
8 |
92 |
22: Расстановки ферзей - 2
Решите предыдущую задачу при ограничении n≤10, если расстановки ферзей, которые можно получить друг из друга поворотами и отражениями доски считать за одно.
| Ввод | Вывод |
|---|---|
8 |
12 |
23: Грузоподъемность
Грузоподъемность машины M килограмм. Есть n ящиков с грузами, масса i-го ящика равна mi. Определите, какую наибольшую массу грузов можно увезти на автомашине.
Программа получает на вход действительное число M, затем количество ящиков n≤20, затем n действительных чисел: массы ящиков.
Программа должна вывести единственное число: максимальную массу, которую можно увезти на машине.
| Ввод | Вывод |
|---|---|
10 |
9.0 |
1073.15936137 |
1064.0876642465998 |
24: Грузоподъемность - 2
Решите предыдущую задачу в ограничениях n≤23. Используйте следующие оптимизации:
- Отсортировать массы грузов по убыванию. Перебор начинать с более тяжелых грузов, сначала рассматриваем вариант, когда очередной груз берется.
- Делается отсечение, если суммарная масса всех взятых грузов превышает вместимость машины.
- Делается отсечение, если суммарная масса всех взятых грузов и всех оставшихся грузов меньше наилучшего уже найденного результата (т.е. если заведомо не удастся улучшить результат).
- Для быстрого определения суммарной массы всех оставшихся грузов используется предподсчет.
25: Задача коммивояжера
На плоскости даны n точек. Соедините их замкнутой ломаной линией минимальной длины.
Программа получает на вход число n≤10. Далее идет n действительных чисел: координаты точек.
Выведите одно действительное число: минимальную длину замкнутой ломаной, проходящей через все эти точки. Ответ выводите с точностью в 15 знаков.
| Ввод | Вывод |
|---|---|
4 |
4.82842712474619 |
26: Задача коммивояжера - 2
Решите задачу коммивояжера в ограничениях n≤11. Используйте следующую оптимизацию:
27: Задача коммивояжера - 3
Решите задачу коммивояжера в ограничениях n≤12. Используйте следующую оптимизацию:
28: Равенство
Дано выражение: a1?a2?...?an=S
Посчитайте, сколькими способами в этом выражении можно заменить вопросительные знаки на знаки операций сложения и умножения так, чтобы выполнялось равенство.
Программа получает на вход число n и S. Далее идет n натуральных чисел ai.
Выведите одно число — количество расстановок знаков сложения и умножения, дающих верное равенство.
| Ввод | Вывод |
|---|---|
2 4 |
2 |
29: Обход доски
Дана шахматная доска размером n×m. Необходимо построить обход всей доски ходом коня так, чтобы конь побывал во всех клетках доски ровно по одному разу. Вы должны сдать на проверку текстовый файл, содержащий nm строчек. Каждая строчка должна содержать координаты ровно одной клетки. Две соседние координаты должны быть связаны ходом коня и каждая из nm клеток доски должна встречаться в этом файле ровно один раз. Каждая клетка записывается в виде “a1”, где сначала записывается одна из первых n букв латинского алфавита, затем число от 1 до m. Например, для доски 4×5 сданный файл может быть таким:
| Вывод |
|---|
a1 c2 d4 b5 a3 b1 d2 c4 a5 b3 c1 a2 b4 d5 c3 d1 b2 a4 c5 d2 |
Сдайте в тестовую систему файл с путём на доске 20×20. (Ваша программа может работать сколь угодно долго, хоть неделю.)
Кроме этого, сдайте программу, которую вы использовали для нахождения ответов. Эта программа не будет проверяться автоматически. Сдать эту программу необходимо как задачу “30”.